1. Introduction¶
A central goal of biological science is to quantitatively understand how genotype influences phenotype. However, despite decades of research, a growing wealth of experimental data, and extensive knowledge of individual molecules and individual pathways, we still do not understand how biological behavior emerges from the molecular level. For example, we do not understand how transcription factors, non-coding RNA, localization signals, degradation tags, and other regulatory systems interact to control protein expression.
Consequently, physicians still cannot interpret the pathophysiological consequences of genetic variation and bioengineers still cannot rationally design microorganisms. Instead, patients often have to try multiple drugs to find a single effective drug, which exposes patients to unnecessary drugs, prolongs disease, and increases costs. Similarly, bioengineers often have to rely on time-consuming and expensive trial and error methods such as directed evolution [4][5].
Many engineering fields use mechanistic models to help understand and design complex systems such as cars [6], buildings [7], and transportation networks [8]. In particular, mechanistic models can help researchers conduct experiments with complete control, precision, and reproducibility.
To comprehensively understand cells, we must develop whole-cell (WC) computational models that predict cellular behavior by representing all of the biochemical activity inside cells [9][10][11][12]. WC models could accelerate biological science by helping researchers unify our knowledge of cell biology, identify gaps in our understanding, and conduct complex experiments that would be infeasible in vitro. WC models could also help bioengineers design microorganisms and help physicians personalize medicine.
Since the 1950’s, researchers have been using modeling to understand cells. This has led to numerous models of individual pathways, including models of cell cycle regulation, chemical and electrical signaling, circadian rhythms, metabolism, and transcriptional regulation. Collectively, these efforts have used a wide range of mathematical formalisms including Boolean networks, flux balance analysis (FBA) [13][14][15], ordinary differential equations (ODEs), partial differential equations (PDEs), and stochastic simulation [16].
Over the last 20 years, researchers have begun to build more comprehensive models that represent multiple pathways [17][18][19][20][21][22][23]. Many of these models have built by combining multiple mathematically-dissimilar submodels of individual pathways into a single multi-algorithmic model [24][3].
Although we do not yet have all of the data and methods needed to model entire cells, we believe that WC models are rapidly becoming feasible due to ongoing advances in measurement and computational technology. In particular, we now have a wide array of experimental methods for characterizing cells, numerous repositories which contain much of the data needed for WC modeling, and a variety of tools for extrapolating experimental data to other organisms and conditions. In addition, we now have a wide range of modeling and simulation tools, including tools for designing models, rule-based model formats for describing complex models, and tools for simulating multi-algorithmic models. However, few of these resources support the scale required for WC modeling, and many these resources remain siloed.
Nevertheless, we and others are beginning to model entire cells [17][25][26][27][28]. In 2012, we and others reported the first dynamical model that represents all of the characterized genes in a cell [27]. The model represents 28 pathways of the small bacterium Mycoplasma genitalium and predicts the essentiality of its genes with 80% accuracy.
However, several bottlenecks remain to build more comprehensive and more accurate WC models. In particular, we do not yet have all of the data needed for WC modeling or tools for designing, describing, or simulating WC models. To accelerate WC modeling, we must develop new methods for characterizing the single-cell dynamics of each metabolite and protein; develop new methods for scalably designing, simulating, and calibrating high-dimensional dynamical models; develop new standards for describing and verifying dynamical models; and assemble an interdisciplinary WC modeling community.
In this part, we summarize the scientific, engineering, and medical problems which are motivating WC modeling; propose the phenotypes that WC models should aim to predict and the molecular mechanisms that WC models should aim to represent; outline the fundamental challenges of WC modeling; describe why WC models are feasible by reviewing the existing methods, data, and models which could be leveraged for WC modeling; review the latest WC models and their limitations; outline the most immediate bottlenecks to WC modeling; propose a plan for achieving WC models; and summarize ongoing efforts to advance WC modeling.
1.1. Motivation for WC modeling¶
In our opinion, WC modeling is motivated by the needs to understand biology, personalize medicine, and design microorganisms. Biological science needs comprehensive models that represent the sequence, function, and interactions of each gene to help scientists holistically understanding cell biology. Similarly, precision medicine needs comprehensive models that predict phenotype from genotype to help physicians interpret the pathophysiological impact of genetic variation which can occur in any gene, and synthetic biology requires comprehensive models to help bioengineers rationally design microbial genomes for a wide range of applications.
In addition, WC models could help researchers address specific scientific problems such as determining how transcriptional regulation, non-coding RNA, and other pathways combine to regulate protein expression. Furthermore, each WC model could be used to address multiple questions, avoiding the need to build separate models for each question. However, few scientific problems require WC models, and we believe that most scientific problems would be more easily addressed with focused modeling.
Here, we describe the main applications which are motivating WC modeling. In the following sections, we define the biology that WC models must represent to support these applications and describe how to achieve such WC models.
1.1.1. Biological science: understand how genotype influences phenotype¶
Historically, the main motivation for WC modeling has been to help scientists understand how genotype and the environment determine phenotype, including how each individual gene, reaction, and pathway contributes to cellular behavior. For example, WC models could help researchers integrate heterogeneous experimental data about multiple genes and pathways. WC models could also help researchers gain novel insights into how pathways interact to control behavior. By comparison to experimental data, WC models could also help researchers identify gaps in our understanding. In addition, WC models would enable researchers to conduct experiments with complete control, infinite scope, and unlimited resolution, which would allow researchers to conduct complex experiments that would be infeasible in vitro.
1.1.2. Medicine: personalize medicine for individual genomes¶
Recent studies have shown that each patient has a unique genome, that genetic variation can occur in any gene and pathway, and that small genetic differences can cause patients to respond differentially to the same drugs. Together, this suggests that medicine could be improved by tailoring therapy to each patient’s genome. Physicians are beginning to use data-driven models to tailor medicine to a small number of well-established genetic variants that have large phenotypic effects. Tailoring medicine for all genetic variation requires WC models that represent every gene and that can predict the phenotypic effect of any combination of genetic variation. Such WC models would help physicians predict the most likely prognosis for each patient and identify the best combination of drugs for each patient (Figure 1.1). For example, WC models could help oncologists conduct personalized in silico drug trials to identify the best chemotherapy regimen for each patient. Similarly, WC models could help obstetricians identify diseases in early fetuses. In addition, WC models could help pharmacologists avoid harmful gene-drug interactions.
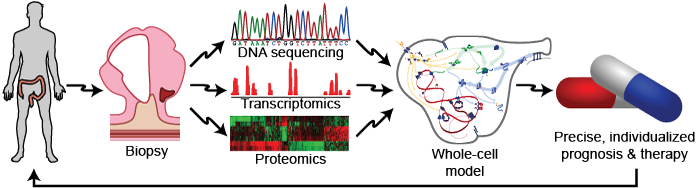
Figure 1.1 WC models could transform medicine by helping physicians use patient-specific models informed by genomic data to design personalized prognoses and therapies.¶
1.1.3. Synthetic biology: rationally design microbial genomes¶
Synthetic biology promises to create microorganisms for a wide range of industrial, medical, security applications such as cheaply producing chemicals, drugs, and fuels; quickly detecting diseased tissue; killing pathogenic bacteria; and decontaminating industrial waste. Currently, microorganisms are often engineered using directed evolution [4][5]. However, directed evolution is often time-consuming and limited to small phenotypic changes. Recently, researchers at the JCVI have begun to pioneer methods for chemically synthesizing entire genomes [29]. Realizing the full potential of this methodology requires WC models that can help bioengineers design entire genomes. For example, WC models could help bioengineers analyze the impact of synthetic circuits on host cells, design efficient chassis for synthetic circuits, and design bacterial drug delivery systems that can detect diseased tissue and synthesize drugs in situ.
1.2. The biology that WC models should aim to represent and predict¶
In the previous section, we argued that medicine and bioengineering need comprehensive models that can predict phenotype from genotype. Here, we outline the specific phenotypes that we believe that WC models should aim to predict and the specific physiochemical mechanisms that we believe that WC models should aim to represent to support medicine and bioengineering (Figure 1.2). In the following sections, we outline why we believe that WC models are becoming feasible and describe how to build and simulate WC models.

Figure 1.2 The physical and chemical mechanisms that WC models should aim to represent (a) and the phenotypes that WC models should aim to predict (b).¶
1.2.1. Phenotypes that WC models should aim to predict¶
To support medicine and bioengineering, we believe that WC models should aim to predict the phenotypes of individual cells over their entire life cycles (Figure 1.2b). Specifically, we believe that WC models should aim to predict the following five levels of phenotypes:
Stochastic dynamics: To help physicians understand how genetic variation affects how cells respond to drugs, and to help bioengineers design microorganisms that are robust to stochastic variation, WC models should predict the stochastic behavior of each molecular species and molecular interaction. For example, this would help physicians design drugs that are robust to variation in RNA splicing, protein modification, and protein complexation. This would also help bioengineers design feedback loops that can control the expression of key RNA and proteins.
Temporal dynamics: To help physicians understand the impact of genetic variation on cell cycle regulation, and to help bioengineers control the temporal dynamics of microorganisms, WC models should predict the temporal dynamics of the concentration of each molecular species. For example, this would help physicians identify genetic variation that can disrupt cell cycle regulation and cause cancer. This would also help bioengineers design microorganisms that can perform specific tasks at specific times.
Spatial dynamics: To help physicians predict the intracellular distribution of drugs, and to help bioengineers use space to concentrate and insulate molecular interactions, WC models should predict the concentration of each molecular species in each spatial domain. For example, this would help physicians predict whether drugs interact with their intended targets and predict how quickly cells metabolize drugs. This would also help bioengineers maximize the metabolic activity of microorganisms by co-localizing enzymes and their substrates.
Single-cell variation: To help physicians understand how drugs affect populations of heterogeneous cells, and to help bioengineers design robust microorganisms, WC models should predict the single-cell variation of cellular behavior. For example, this would help physicians understand how chemotherapies affect heterogeneous tumors, and help bioengineers design reliable biosensors that activate at the same threshold irrespective of stochastic variation in RNA and protein expression.
Complex phenotypes: To help physicians understand the impact of variation on complex phenotypes and to help bioengineers design microorganisms that can perform complex phenotypes, WC models should predict complex phenotypes such as the cell shape, growth rate, and fate. For example, this would help physicians identify the primary variants responsible for disease and help physicians screen drugs in silico. This would also help bioengineers design sophisticated strains that can detect tumors, synthesize chemotherapeutics, and deliver drugs directly to tumors.
1.2.2. Physics and chemistry that WC models should aim to represent¶
To predict these phenotypes, we believe that WC models should aim to represent all of the chemical reactions inside cells and all of the physical processes that influence their rates (Figure 1.2a). Specifically, we propose that WC models aim to represent the following seven aspects of cells:
Sequences: To predict how genotype influence phenotype, including the contribution of each individual variant and gene, WC models should represent the sequence of each chromosome, RNA, and protein; the location of each feature of each chromosome such as genes, operons, promoters, and terminators; and the location of each site of each RNA and protein.
Structures: To predict how molecular species interact and react, WC models should represent the structure of each molecule, including atom-level information about small molecules, the domains and sites of macromolecules, and the subunit composition of complexes. For example, this would enable WC models to predict the metabolism of novel compounds.
Subcellular organization: To capture the molecular interactions that occur inside cells, WC models should represent the spatial organization of cells and the localization of each of metabolite, RNA, and protein species. For example, this would enable WC models to predict the spatial compartments in which molecular interactions occur.
Concentrations: To capture the molecular interactions that can occur inside cells, WC models should also represent the concentration of each molecular species in each organelle and spatial domain.
Molecular interactions: To capture how cells behave over time, WC models should represent the participants and effect of each molecular interaction, including the molecules that are consumed, produced, and transported, the molecular sites that are modified, and the bonds that are broken and formed. For example, this would enable WC models to capture the reactions responsible for cellular growth and homeostatic maintenance.
Kinetic parameters: To predict the temporal dynamics of cell behavior, WC models should represent the kinetic parameters of each interaction such as the maximum rate of each reaction and the affinity of each enzyme for its substrates and inhibitors. For example, this would enable WC models to predict the impact of genetic variation on the function of each enzyme.
Extracellular environment: To predict how the extracellular environment, including nutrients, hormones, and drugs, influences cell behavior, WC models should represent the concentration of each species in the extracellular environment. For example, this should enable WC models to predict the minimum media required for growth.
1.3. Fundamental challenges to WC modeling¶
In the previous section, we defined the biology that WC models should represent and predict. Building WC models that represent all of the biochemical activity inside cells and that can predict any cellular phenotype is challenging because this requires integrating molecular behavior to the cellular level across several spatial and temporal scales; assembling a complete molecular understanding of cell biology from incomplete, imprecise, and heterogeneous data; and simulating, calibrating, and validating computationally-expensive, high-dimensional models. Here, we describe these challenges to WC modeling. In the following sections, we describe emerging methods for overcoming these challenges to achieve WC models.
1.3.1. Integrating molecular behavior to the cell level over several spatiotemporal scales¶
The most fundamental challenge to WC modeling is integrating the behavior of individual species and reactions to the cellular level over several spatial and temporal scales. This is challenging because it requires accurate parameter values and scalable methods for simulating large models. Here, we summarize these challenges.
1.3.1.1. Sensitivity of phenotypic predictions to molecular parameter values¶
The first challenge to integrating molecular behavior to the cellular level is the sensitivity of model predictions to the values of critical parameters, which necessitates accurate parameter values. Accurately identifying these values is challenging because, as described below, it is challenging to optimize high-dimensional functions and because, as described in Section 1.3.1, our experimental data is incomplete and imprecise.
1.3.1.2. High computational cost of simulating large fine-grained models¶
A second challenge to integrating molecular behavior to the cellular level is the high computational cost of simulating entire cells with molecular granularity. For example, simulating one cell cycle of our first WC model of the smallest known freely living organism took a full core-day of an Intel E5520 CPU, or approximately \(1 \times 10^{15}\) floating-point operations [27]. Based on this data, the fact that human cells are approximately 106 larger, and the fact that a typical WC simulation experiment will require at least 1,000 simulation runs, a typical WC simulation experiment of a human cell will require approximately 106 core-years. To simulate larger and more complex organisms, we must develop faster parallel simulators.
1.3.2. Assembling a unified molecular understanding of cells from imperfect data¶
In our opinion, the greatest challenge to WC modeling is assembling a unified molecular understanding of cell biology. As illustrated in Figure 1.3, this requires assembling comprehensive data about every molecular species and molecular interaction. For example, to model M. genitalium we reconstructed (a) its subcellular organization; (b) its chromosome sequence; (c) the location, length, direction and essentiality of each gene; (d) the organization and promoter of each transcription unit; (e) the expression and degradation rate of each RNA transcript; (f) the specific folding and maturation pathway of each RNA and protein species including the localization, N-terminal cleavage, signal sequence, prosthetic groups, disulfide bonds and chaperone interactions of each protein species; (g) the subunit composition of each macromolecular complex; (h) its genetic code; (i) the binding sites and footprint of every DNA-binding protein; (j) the structure, charge and hydrophobicity of every metabolite; (k) the stoichiometry, catalysis, coenzymes, energetics and kinetics of every chemical reaction; (l) the regulatory role of each transcription factor; (m) its chemical composition and (n) the composition of its growth medium [30].
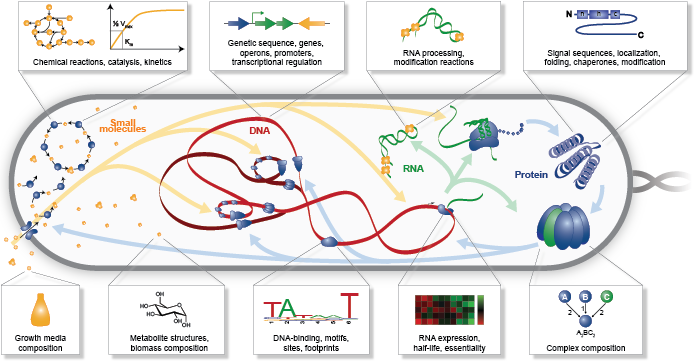
Figure 1.3 WC models require comprehensive data about every molecular species and molecular interaction.¶
This is challenging because our data is incomplete, imprecise, heterogeneous, scattered, and poorly annotated. Here, we summarize these limitations and the challenges they present for WC modeling.
1.3.2.1. Incomplete data¶
The biggest limitation of our experimental data is that we do not have a complete experimental characterization of a cell. In particular, we have limited genome-scale data about individual metabolites and proteins, limited data about cell cycle dynamics, limited data about cell-to-cell variation, limited data about culture media, and limited data about cellular responses to genetic and environmental perturbations. Many genome-scale datasets are also incomplete. For example, most metabolomics and proteomics methods can only measure small numbers of metabolites and proteins.
1.3.2.2. Imprecise and noisy data¶
A second limitation of our experimental data is that many of our measurement methods are imprecise and noisy. For example, fluorescent microscopy cannot precisely quantitate single-cell protein abundances, single-cell RNA sequencing cannot reliably discern unexpressed RNA, and mass-spectrometry cannot reliably discern unexpressed proteins.
1.3.2.3. Heterogeneous experimental methods¶
A third limitation of our experimental data is that our data is highly heterogeneous because we do not have a single experimental technology that is capable of completely characterizing a cell. Rather, we have a wide range of methods for characterizing different aspects of cells at different scales with different levels of resolution. For example, mass-spectrometry can quantitate the concentrations of tens of metabolites, deep sequencing can quantitate the concentrations of tens of thousands RNA, and each biochemical experiment can quantitate one or a few kinetic parameters.
Consequently, our experimental data also spans a wide range of scales and units. For example, we have extensive molecular information about the participants in each metabolic reaction and their stoichiometries, but we only have limited information about the substrates of each protein chaperone. As a second example, we have extensive single-cell information about RNA expression, but we have limited single-cell data about metabolite concentrations.
1.3.2.4. Heterogeneous organisms and environmental conditions¶
A fourth limitation of our data is that we only have a small amount of data about each organism and environmental condition, and only a small amount of data from each laboratory. However, collectively, we have a large amount of data.
1.3.2.5. Siloed data¶
Another limitation of our data is that no resource contains all of the data needed for WC modeling. Rather, our data is scattered across a wide range of databases, websites, textbooks, publications, supplementary materials, and other resources. For example, ArrayExpress [31] and the Gene Expression Omnibus [32] (GEO) only contain RNA abundance data, PaxDb only contains protein abundance data [33], and SABIO-RK only contains kinetic data [34]. Furthermore, many of these data sources use different identifiers and different units.
1.3.2.6. Insufficient annotation¶
Furthermore, much of our data is insufficiently annotated to understand its biological semantic meaning and provenance. For example, few RNA-seq datasets in ArrayExpress [31] have sufficient metadata to understand the environmental condition that was measured, including the concentration of each metabolite in the growth media and the temperature and pH of the growth media. Similarly, few kinetic measurements in SABIO-RK [34] have sufficient metadata to understand the strain that was measured.
1.3.3. Selecting, calibrating and validating high-dimensional models¶
A third fundamental challenge to WC modeling is the high-dimensionality of WC models which makes WC models susceptible to the “curse of dimensionality”, the need for more data to constrain high-dimensional models [1]. In particular, the curse of dimensionality makes it challenging to select, calibrate, and validate WC models because we do not yet have sufficient data to data to select among multiple possible WC models, avoid overfitting WC models, precisely determine the value of each parameter, or test the accuracy of every possible prediction. Furthermore, it is computationally expensive to select, calibrate, and validate high-dimensional models.
1.4. Feasibility of WC models¶
Despite the numerous challenges to WC modeling described in the previous section, we believe that WC modeling is rapidly becoming feasible due to ongoing technological advances throughout computational systems biology, bioinformatics, genomics, molecular cell biology, applied mathematics, computer science, and software engineering including methods for experimentally characterizing cells, repositories for sharing data, tools for building and simulating dynamical models, models of individual pathways, and model repositories. While substantial work remains to adapt and integrate these technologies into a unified framework for WC modeling, these technologies are already forming a strong intellectual foundation for WC modeling. Here, we review the technologies that we believe are making WC modeling feasible, and describe their present limitations for WC modeling. In the following section, we describe how we are beginning to leveraging these technologies to build and simulate WC models.
1.4.1. Experimental methods, data, and repositories¶
Here, we review advances in measurement methods, data repositories, and bioinformatics tools that are generating the data needed for WC modeling, aggregating this data into repositories, and producing tools for extrapolating data to other genotypes and environments.
1.4.1.1. Measurement methods¶
Advances in biochemical, genomic, and single-cell measurement are rapidly generating the data needed for WC modeling [35][36][37] (Table 1.1). For example, Meth-Seq can assess epigenetic modifications [38], Hi-C can determine the average structure of chromosomes [39], ChIP-seq can determine protein-DNA interactions [40], fluorescence microscopy can determine protein localizations, mass-spectrometry can quantitate average metabolite concentrations, scRNA-seq [41][42] can quantitate the single-cell variation of each RNA [41], FISH [43] can quantitate the spatiotemporal dynamics and single-cell variation of the abundances of a few RNA, mass spectrometry can quantitate the average abundances of hundreds of proteins [44][45], mass cytometry can quantitate the single-cell variation of the abundances of tens of proteins [46], and fluorescence microscopy can quantitate the spatiotemporal dynamics and single-cell variation of the abundances of a few proteins. However, improved methods are still needed to measure the dynamics of the entire metabolome and proteome.
Data type |
URL |
Reference |
|---|---|---|
Metabolites |
||
Structure |
||
Mass spectrometry |
Dettmer et al., 2007 |
|
Concentration |
||
Fluorescence microscopy |
Zenobi, 2013 |
|
Mass spectrometry |
Dettmer et al., 2007 |
|
Spectrophotometry |
TeSlaa and Teitell, 2014 |
|
DNA |
||
Structure |
||
DNA sequencing |
Shendure and Ji, 2008 |
|
Methylation sequencing |
Laird, 2010 |
|
Chromosome conformation capture |
Dekker et al., 2013 |
|
Concentration |
||
Flow cytometry |
Bendall et al., 2012 |
|
RNA |
||
Structure |
||
RNA sequencing |
Ozsolak and Milos, 2011 |
|
Modification sequencing (ICE, MERIP-Seq) |
Liu and Pan, 2015 |
|
X-ray crystallography |
Reyes et al., 2009 |
|
Localization |
||
Fluorescence in situ hybridization |
Lee et al., 2014 |
|
Transcription rate |
||
ChIP-seq |
Park, 2009 |
|
GRO-seq |
Core et al., 2008 |
|
Half-life |
||
Microarray timecourse |
Selinger et al., 2003 |
|
RNA sequencing timecourse |
Schwanhäusser et al., 2011 |
|
Concentration |
||
Microarray |
Schulze and Downward, 2001 |
|
RNA sequencing |
Ozsolak and Milos, 2011 |
|
Fluorescence in situ hybridization |
Taniguchi et al., 2010 |
|
Proteins |
||
Structure |
||
Mass spectrometry |
Domon and Aebersold, 2006 |
|
Nuclear magnetic resonance spectroscopy |
Tugarinov et al., 2004 |
|
RNA sequencing |
Ozsolak and Milos, 2011 |
|
X-ray crystallography |
Ilari and Savino, 2008 |
|
Localization |
||
Fluorescence microscopy |
Giepmans et al., 2006 |
|
Translation rate |
||
Ribosomal profiling |
Ignolia, 2014 |
|
Half-life |
||
Fluorescence timecourse |
Knop and Edgar, 2014 |
|
Mass spectrometry timecourse |
Schwanhäusser et al., 2011 |
|
Concentration |
||
Flow cytometry |
Bendall et al., 2012 |
|
Fluorescence microscopy |
Giepmans et al., 2006 |
|
Mass cytometry |
Bendall et al., 2012 |
|
Mass spectrometry |
Domon and Aebersold, 2006 |
|
Spectrophotometery |
Noble and Bailey, 2009 |
|
Interactions |
||
RNA-DNA |
||
CHIRP-Seq |
Chu et al., 2011 |
|
Protein-metabolite |
||
Mass spectrometry |
Domon and Aebersold, 2006 |
|
Protein-DNA |
||
ChIP-seq |
Park, 2009 |
|
DNase-seq |
Song and Crawford, 2010 |
|
Protein-RNA |
||
CLIP-seq |
Darnell, 2010 |
|
RIP-seq |
Zhao et al., 2010 |
|
Protein-protein |
||
Co-immunoprecipitation |
Sambrook and Russell, 2006 |
|
Tandem affinity purification |
Xu et al., 2010 |
|
Two-hybrid screen |
Brückner et al., 2009 |
|
Reaction fluxes |
||
Isotopic labeling |
Klein and Heinzle, 2012 |
|
Phenotypic data |
||
Cell size |
||
Fluorescence microscopy |
Muzzey and van Oudenaarden, 2009 |
|
Growth rates |
||
Spectrophotometery |
Jensen et al., 2015 |
|
Division times |
||
Fluorescence microscopy |
Wang et al., 2010 |
|
Motility, chemotaxis |
||
Fluorescence microscopy |
Dormann and Weijer, 2006 |
1.4.1.2. Data repositories¶
Researchers are rapidly aggregating the experimental data needed for WC modeling into repositories (Table 1.2). This includes specialized repositories for individual types of data such as ECMDB [47] and YMDB [48] for metabolite concentrations; ArrayExpress [31] and the Gene Expression Omnibus [32] (GEO) for RNA abundances; PaxDb [33] for protein abundances; BiGG [49] for metabolic reactions, and SABIO-RK for kinetic parameters [34], as well as general purpose repositories such as FigShare [50], SimTk [51], and Zenodo [52].
Some researchers are making the data in these repositories more accessible by providing common interfaces to multiple repositories such as BioMart [53], BioServices [54], and Intermine [55].
Other researchers are making the data in these repositories more accessible by integrating the data into meta-databases. For example, KEGG contains a variety of information about metabolites, proteins, reactions, and pathways [56]; Pathway Commons contains extensive information about protein-protein interactions and pathways [57]; and UniProt contains a multitude of information about proteins [58].
In addition, some researchers are integrating information about individual organisms into PGDBs such as the BioCyc family of databases [59][60]. These databases contain a wide range of information including the stoichiometries of individual reactions, the compositions of individual protein complexes, and the genes regulated by individual transcription factors. Because PGDBs already contain integrated data about a single organism, PGDBs could readily be leveraged to build WC models. In fact, Latendresse developed MetaFlux to build constraint-based models of metabolism from EcoCyc [61].
Furthermore, meta-databases such as Nucleic Acid Research’s Database Summary [62] and re3data.org [63] contain lists of data repositories.
Most of these repositories have been developed by encouraging individual researchers to deposit their data or by employing curators to manually extract data from publications, supplementary files, and websites. In addition, researchers are beginning to use natural language processing to develop tools for automatically extracting data from publications [64].
Database |
Content |
URL |
Reference |
|---|---|---|---|
Species structures |
|||
Metabolites |
|||
ChEBI |
Compound structures |
Hastings et al., 2016 |
|
KEGG Compound |
Compound structures |
Kanehisa et al., 2017 |
|
KEGG Glycan |
Glycan structures |
Hashimoto et al., 2006 |
|
Metabolomics Workbench Metabolite Database |
Compound structures |
Sud et al., 2016 |
|
LIPID MAPS |
Lipid structures |
Sud et al., 2007 |
|
PubChem |
Compound structures |
Kim et al., 2016 |
|
DNA |
|||
ArrayExpress |
Functional genomics data including Hi-C data |
Kolesnikov et al., 2015 |
|
GenBank |
DNA sequences |
Benson et al., 2017 |
|
GEO |
Functional genomics data including Hi-C data |
Clough and Barrett, 2016 |
|
MethDB |
Methylation sequencing data |
Grunau et al., 2001 |
|
RNA |
|||
ArrayExpress |
Functional genomics data including RNA-seq data that encompasses initiation and termination sites |
Kolesnikov et al., 2015 |
|
GEO |
Functional genomics data including RNA-seq data that encompasses initiation and termination sites |
Clough and Barrett, 2016 |
|
MODOMICS |
Post-transcriptional modifications |
Machnicka et al., 2013 |
|
RNA Modification Database |
Post-transcriptional modifications |
Cantara et al., 2011 |
|
Protein |
|||
3d-footprint |
3-dimensional footprints |
Contreras-Moreira, 2010 |
|
dbPTM |
Post-translational modifications |
Huang et al., 2016 |
|
PDB |
3-dimensional structures |
Rose et al., 2017 |
|
RESID |
Post-translational modifications |
Garavelli, 2004 |
|
UniMod |
Post-translational modifications |
Creasy and Cottrell, 2004 |
|
UniProt |
Functional protein annotations including post-translational modifications |
The UniProt Consortium, 2017 |
|
Localization and signal sequences |
|||
RNA |
|||
Fly-FISH |
RNA localizations |
Wilk et al., 2006 |
|
RNALocate |
RNA localizations |
Zhang et al., 2017 |
|
Protein |
|||
COMPARTMENTS |
Protein localizations for Arabidopsis thaliana, Caenorhabditis elegans, Drosophila melanogaster, Homo sapiens, Mus musculus, and Rattus norvegicus |
Binder et al., 2014 |
|
Human Protein Reference Database |
Protein localizations for Homo sapiens |
Prasad et al., 2009 |
|
LOCATE |
Protein localizations for Homo sapiens and Mus musculus |
Sprenger et al., 2008 |
|
LocDB |
Protein localizations for Arabidopsis thaliana and Homo sapiens |
Rastogi and Rost, 2011 |
|
LocSigDB |
Protein localizations for eukaryotes |
Negi et al., 2015 |
|
OrganelleDB |
Protein localizations |
Wiwatwattana et al., 2007 |
|
PSORTdb |
Protein localizations for bacteria and archaea |
Peabody et al., 2016 |
|
UniProt |
Functional protein annotations including protein localizations |
The UniProt Consortium, 2017 |
|
Concentrations |
|||
Metabolites |
|||
BioNumbers |
Quantitative measurements of physical, chemical, and biological properties including metabolite concentrations |
Milo et al., 2010 |
|
ECMBD |
Metabolite concentrations in Escherichia coli |
Sajed et al., 2016 |
|
HMDB |
Metabolite concentrations in Homo sapiens |
Wishart et al., 2013 |
|
MetaboLights |
Kale et al., 2016 |
||
YMDB |
Metabolite concentrations in Saccharomyces cerevisiae |
Ramirez-Gaona et al., 2017 |
|
RNA |
|||
ArrayExpress |
Functional genomics data including RNA abundances from microarray and RNA-seq experiments |
Kolesnikov et al., 2015 |
|
Expression Atlas |
RNA abundances across organisms and environmental conditions |
Petryszak et al., 2016 |
|
GEO |
Functional genomics data including RNA abundances from microarray and RNA-seq experiments |
Clough and Barrett, 2016 |
|
Proteins |
|||
Review |
Perez-Riverol et al., 2015 |
||
Human Protein Atlas |
Protein abundances for Homo sapiens |
Uhlén et al., 2015 |
|
PaxDb |
Protein abundances |
Wang et al., 2015 |
|
Plasma Proteome Database |
Protein abundances for Homo sapiens plasma |
Nanjappa et al., 2014 |
|
PRIDE |
Mass-spectrometry proteomics data |
Vizcaíno et al., 2016 |
|
Interactions |
|||
Protein-Metabolite, See also: Cofactors |
|||
Review |
Matsuda et al., 2014 |
||
DrugBank |
Drugs and their targets |
Law et al., 2014 |
|
STITCH |
Drugs and their targets |
Szklarczyk et al., 2016 |
|
SuperTarget |
Drugs and their targets |
Hecker et al., 2012 |
|
Therapeutic Targets Database |
Drugs and their targets |
Zhu et al., 2012 |
|
Protein-DNA |
|||
ArrayExpress |
Functional genomics data including ChIP-seq data of protein-DNA interations |
Kolesnikov et al., 2015 |
|
GEO |
Functional genomics data including ChIP-seq data of protein-DNA interations |
Clough and Barrett, 2016 |
|
DBD |
Predicted transcription factors |
Wilson et al., 2008 |
|
DBTBS |
Bacillus subtilis transcription factors and the operons they regulate |
Sierro et al., 2008 |
|
ORegAnno |
Transcription factor binding sites |
Lesurf et al., 2016 |
|
TRANSFAC |
Transcription factor binding motifs |
Matys et al., 2003 |
|
UniProbe |
Transcription factor binding motifs |
Hume et al., 2015 |
|
Protein-Protein |
|||
Review |
Lehne et al., 2009 |
||
ConsensusPathDB |
Homo sapiens molecular interactions including protein-protein interactions |
Kamburov et al., 2013 |
|
BioGRID |
Protein-protein interactions |
Chatr-aryamontri et al., 2017 |
|
CORUM |
Protein complex composition |
||
DIP |
Protein-protein interactions |
Salwinski et al., 2004 |
|
IntAct |
Molecular interactions including protein-protein interactions |
Szklarczyk et al., 2017 |
|
STRING |
Protein-protein interactions |
Kerrien et al., 2012 |
|
UniProt |
Function protein annotations including protein complex compositions |
The UniProt Consortium, 2017 |
|
Reactions |
|||
Stoichiometries, catalysis |
|||
BioCyc |
Reaction stoichiometries and catalysts |
Caspi et al., 2016 |
|
KEGG |
Reaction stoichiometries and catalysts |
Kanehisa et al., 2017 |
|
MACiE |
Detailed reaction mechanisms |
Holliday et al., 2012 |
|
Rhea |
Reaction stoichiometries |
Morgat et al., 2017 |
|
UniProt |
Reaction stoichiometries and catalysts |
The UniProt Consortium, 2017 |
|
Cofactors |
|||
CoFactor |
Organic enzyme cofactors |
Fischer et al., 2010 |
|
PDB |
3-dimensional protein structures including cofactors |
Rose et al., 2017 |
|
UniProt |
Functional protein annotations including cofactors |
The UniProt Consortium, 2017 |
|
Rate laws and rate constants |
|||
BioNumbers |
Quantitative measurements of physical, chemical, and biological properties including kinetic parameters |
Milo et al., 2010 |
|
BRENDA |
Kinetic parameters and rate laws |
Schomburg et al., 2017 |
|
SABIO-RK |
Kinetic parameters and rate laws |
Wittig et al., 2012 |
|
Pathways |
|||
Metabolic |
|||
Review |
Karp and Caspi, 2011 |
||
BioCyc |
Species-specific pathways |
Caspi et al., 2016 |
|
KEGG PATHWAY |
Species-specific pathways |
Kanehisa et al., 2017 |
|
Signaling |
|||
Review |
Chowdhury and Sarkar, 2015 |
||
hiPathDB |
Metadatabase of Homo sapiens signaling pathways |
Yu et al., 2012 |
|
KEGG PATHWAY |
Pathways including signaling pathways |
Kanehisa et al., 2017 |
|
NetPath |
Immune signaling pathways |
Kandasamy et al., 2010 |
|
PANTHER Pathway |
Pathways including signaling pathways |
Mi et al., 2017 |
|
Pathway Commons |
Metadatabase of signaling pathways |
Cerami et al., 2011 |
|
Reactome |
Pathways including signaling pathways |
Fabregat et al., 2016 |
|
WikiPathways |
Community curated pathways including signaling pathways |
Kutmon et al., 2016 |
|
Meta-databases and meta-database tools |
|||
Review |
Urdidiales-Nieto et al., 2017 |
||
BioCatalogue |
List of web services |
Bhagat et al., 2010 |
|
BioMart |
Tools for integrating data from multiple repositories |
Kasprzyk, 2010 |
|
BioMoby |
Ontology-based messaging system for discovering data |
BioMoby Consortium et al., 2008 |
|
BIOSERVICES |
Python APIs to several popular repositories |
Cokelaer et al., 2013 |
|
BioSWR |
List of web services |
Repchevsky and Gelpi, 2014 |
|
ELIXIR |
Effort to develop a common data infrastructure for Europe |
Crosswell and Thornton, 2012 |
|
NAR Database Summary |
List of database papers published in Nucleic Acids Research database issues |
Galperin et al., 2017 |
|
re3data.org Registry |
List of data repositories |
Pampel et al., 2013 |
1.4.1.3. Prediction tools¶
Accurate prediction tools can be a useful alternative to constraining models with direct experimental evidence. Currently, many tools can predict molecular properties such as the organization of genes into operons, RNA folds, and protein localizations (Table 1.3). For example, PSORTb can predict the localization of bacterial proteins [65] and TargetScan can predict the mRNA targets of small non-coding RNAs [66]. In particular, these tools can be used to impute missing data and extrapolate observations to other organisms, genetic conditions, and environmental conditions. However, many current prediction tools are not sufficiently accurate for WC modeling.
Tool |
Prediction(s) |
Language |
URL |
Reference |
|---|---|---|---|---|
Metabolites |
||||
Physical properties |
||||
Review |
Survey of several chemoinformatic packages |
O’Boyle et al., 2011 |
||
Chemistry Development Kit (CDK) |
Java libraries for processing chemical information |
Java |
Steinbeck et al., 2006 |
|
Cinfony |
A common API to several cheminformatics toolkits |
Python |
O’Boyle and Hutchison, 2008 |
|
Indigo |
A toolkit for molecular fingerprinting, substructure searching, and visualization |
C++, Java, .Net, Python |
||
JChem |
Tools for draw and visualizing molecules and searching chemical databases |
Java, .Net, REST |
Csizmadia, 2000 |
|
Open Babel |
Tools for searching, converting, analyzing, and storing chemical structures |
C++, Java, .Net, Python |
O’Boyle et al., 2011 |
|
RDKit |
Cheminformatics toolkit |
C++, Python |
||
Thermodynamics |
||||
UManSysProp |
Estimates the standard Gibbs free energy of formation of organic molecules using the Joback group contribution method |
Python, REST |
Joback and Reid, 1987; Topping et al., 2016 |
|
Web GCM |
Estimates the standard Gibbs free energy of formation of organic molecules using the Mavrovouniotis group contribution method |
REST |
Jankowski et al., 2008 |
|
DNA |
||||
Promoters |
||||
Review |
Review of promoter prediction methods for Homo sapiens |
Pedersen et al., 1999 |
||
PePPER |
Predicts prokaryote promoters |
REST |
de Yong et al., 2012 |
|
Promoter |
Predicts vertebrate PolII promoters |
REST |
Knudsen, 1999 |
|
PromoterHunter |
Predicts prokaryote promoters |
REST |
Klucar et al., 2010 |
|
Genes |
||||
Review |
Review of several gene prediction software tools |
https://cmgm.stanford.edu/biochem218/Projects%202007/Mcelwain.pdf |
McElwain, 2007 |
|
GeneMark |
Family of tools for predicting viral, prokaryotic, archaeal, and eukaryotic genes |
Linux executable, REST |
Borodovsky and Lomsadze, 2011 |
|
GENESCAN |
Predicts plant and vertebrate genes |
Linux executable, REST |
Burge and Karlin, 1997 |
|
GLIMMER |
Predicts viral, prokaryotic, and archaeal genes |
C, REST |
Salzberg et al., 1998 |
|
Operons |
||||
Review |
Survey of several operon prediction methods |
Brouwer et al., 2008 |
||
DOOR |
Predicts prokaryotic operons |
REST |
Mao et al., 2014 |
|
OperonDB |
Estimates the likelihood that pairs of genes are in the same operon |
Perl, REST |
Ermolaeva et al., 2001 |
|
ProOpDB |
Predicts prokaryotic operons |
Java, REST |
Taboada et al., 2010 |
|
VIMSS |
Predicts prokaryotic and archaeal operons |
R, REST |
Price et al., 2005 |
|
Variant interpretation |
||||
PolyPhen-2 |
Predicts the functional effects of amino acid substitutions |
C, REST |
Adzhubei et al., 2013 |
|
PROVEAN |
Predicts the functional effects of amino acid substitutions and indels |
C++, REST |
Choi and Chan, 2015 |
|
SIFT |
Predicts the functional effects of amino acid indels |
C++, REST |
Hu and Ng, 2013 |
|
RNA |
||||
Splice sites |
||||
Review |
Review of methods for predicting splice sites |
Desmet et al., 2010 |
||
GeneSplicer |
Predicts eukaryotic splice sites |
Java |
Pertea et al., 2001 |
|
Human Splicing Finder |
Identify and predict mutations’ effect on human splicing motifs |
REST |
Desmet et al., 2009 |
|
NetGene2 |
Predicts splice sites in Arabidopsis thaliana, Caenorhabditis elegans, and Homo sapiens |
REST |
Hebsgaard et al., 1996 |
|
NNSplice |
Predicts splice sites Drosophila melanogaster and Homo sapiens |
REST |
Reese et al., 1997 |
|
Secondary structure |
||||
Review |
Review of methods for predicting RNA secondary structures |
Lorenz et al., 2016 |
||
Mfold |
Predicts RNA secondary structures |
C, REST |
Zuker, 2003 |
|
RNAstructure |
Predicts RNA and DNA secondary structures |
C++, Java |
Reuter and Mathews, 2010 |
|
ViennaRNA |
Predicts RNA secondary structures |
C, Perl, Python |
Lorenz et al., 2011 |
|
Open reading frame |
||||
ORF Finder |
Predicts open reading frames |
Linux executable, REST |
Rombel et al., 2002 |
|
ORF Investigator |
Predicts open reading frames |
Windows executable |
https://sites.google.com/site/dwivediplanet/ORF-Investigator |
Dhar and Kumar, 2012 |
ORFPredictor |
Predicts open reading frames from EST and cDNA sequences |
Perl, REST |
Min et al., 2005 |
|
Terminators |
||||
Review |
Review of prokaryotic transcription termination that cites several methods for predicting terminators. |
Peters et al., 2011 |
||
ARNold |
Predicts prokaryotic rho-independent terminators |
REST |
Gautheret D and Lambert A, 2001 |
|
FindTerm |
Predicts prokaryotic rho-independent terminators |
REST |
http://www.softberry.com/berry.phtml?topic=findterm&group=programs&subgroup=gfindb |
Solovyev and Salamov, 2011 |
GeSTer |
Predicts prokaryotic rho-independent terminators |
REST |
Mitra et al., 2011 |
|
TransTermHP |
Predicts prokaryotic rho-independent terminators |
C++ |
Kingsford et al., 2007 |
|
Proteins |
||||
Localization |
||||
Review |
Review of methods for predicting the subcellular localization of prokaryotic and eukaryotic proteins |
Imai and Nakai, 2010 |
||
Review |
Review of methods for predicting the subcellular localization of prokaryotic proteins |
Gardy and Brinkman, 2006 |
||
Cell-PLoc |
Predicts the subcellular localization of proteins for multiple species |
REST |
Chou and Shen, 2010 |
|
MultiLoc |
Predicts the subcellular localization of proteins for multiple species |
Python, REST |
Blum et al., 2009 |
|
PSORTb |
Predicts the subcellular localization of prokaryotic and archaeal proteins |
C++, Perl, REST |
Yu et al., 2010 |
|
SecretomeP |
Predicts signal peptide-independent protein secretion |
REST, tcsh |
Bendtsen et al., 2004 |
|
WoLF PSORT |
Predicts the subcellular localization of eukaryotic proteins |
Perl, REST |
Horton et al., 2007 |
|
Signal sequence |
||||
Review |
Architecture, function and prediction of long signal peptides |
Hiss and Schneider, 2009 |
||
Phobius |
Predict protein transmembrane topology and signal peptides from AA sequences |
Java, REST |
Käll et al., 2007 |
|
PRED-LIPO |
Predict lipoprotein and secretory signal peptides in gram-positive bacteria |
REST |
Bagos et al., 2008 |
|
PRED-SIGNAL |
Predict signal peptides in archaea |
REST |
Bagos et al., 2009 |
|
SignalP |
Predict signal peptide cleavage sites in prokaryotic and eukaryotic proteins |
Perl, REST |
Petersen et al., 2011 |
|
Disulfide bonds |
||||
Review |
Review of methods predicting disulfide bonds |
Tsai et al., 2007 |
||
Review |
Review of methods predicting disulfide bonds |
Márquez-Chamorro and Aguilar-Ruiz, 2015 |
||
Cyscon |
A consensus model for predicting disulfide bonds |
REST |
Yang et al., 2015 |
|
DIANNA |
Predicts disulfide bonds |
Python, REST |
Ferrè F and Clote P, 2006 |
|
Dinsolve |
Predicts disulfide bonds |
REST |
Yaseen and Li, 2013 |
|
DIPro |
Predicts disulfide bonds |
REST, Perl |
Cheng et al., 2006 |
|
DISULFIND |
Predicts disulfide bonds |
REST |
Ceroni et al., 2006 |
|
Complex abundance |
||||
SiComPre |
Predicts the abundances of Homo sapiens and Saccharomyces cerevisiae protein complexes |
C++, Java, Python |
Rizzetto et al., 2015 |
|
Half-lives |
||||
N-End rule |
Predicts the half-lives of Escherichia coli, Saccharomyces cerevisiae and mammalian (rabit) proteins |
REST |
Bachmair et al., 1986 |
|
Interactions |
||||
miRNA targets |
||||
Review |
Review of methods for predicting miRNA targets |
Bartel, 2009 |
||
Review |
Review of methods for predicting miRNA targets |
Peterson et al., 2014 |
||
DIANA-microT-CDS |
Predicts miRNA targets in Caenorhabditis elegans, Drosophila melanogaster, Homo sapiens, and Mus musculus |
REST |
Reczko et al., 2012 |
|
miRSearch |
Predicts miRNA targets in Homo sapiens, Mus musculus, and Rattus norvegicus |
REST |
||
MirTarget |
Predicts miRNAs targets in several animals |
REST |
Wang, 2016 |
|
PITA |
Predicts miRNA targets in Caenorhabditis elegans, Drosophila melanogaster, Homo sapiens, and Mus musculus |
C, Perl, REST |
Kertesz et al., 2007 |
|
STarMir |
Predicts miRNA targets in Caenorhabditis elegans, Homo sapiens, and Mus musculus |
Perl, R, REST |
Lui et al., 2013 |
|
TargetScan |
Predicts miRNA targets in several animals |
Perl, REST |
Agarwal et al., 2015 |
|
Protein-DNA binding sites |
||||
Review |
Review of tools for predicting transcription factor binding sites |
Tompa et al., 2005 |
||
Review |
Review of tools for predicting transcription factor binding sites |
Jayaram et al., 2016 |
||
DBD |
Predicts DNA-binding domains of transcription factors |
REST |
Wilson et al., 2008 |
|
JASPAR |
Predicts transcription factor binding motifs |
Perl, Python, R, REST, Ruby |
Mathelier et al., 2016 |
|
Weeder |
Predicts likely transcription factor binding motifs |
C++, REST |
Pavesi et al., 2004 |
|
Chaperones |
||||
BiPPred |
Predicts the interactions of mammalian proteins with chaperone BiP |
REST |
Schneider et al., 2016 |
|
cleverSuite |
Predicts the interactions of Escherichia coli proteins with chaperone DnaK/GroEL |
REST |
Klus et al., 2014 |
|
LIMBO |
Predicts the interactions of Escherichia coli proteins with chaperone DnaK |
REST |
Van Durme et al., 2009 |
|
Reaction center and atom mapping |
||||
Review |
Review of methods for reaction mapping and reaction center detection |
Chen et al., 2013 |
||
CAM |
Predicts the mapping of reactant to product atoms |
C++ |
Mann et al., 2014 |
|
CLCA |
Predicts the mapping of reactant to product atoms |
REST |
Kumar and Maranas, 2014 |
|
MWED |
Predicts the mapping of reactant to product atoms |
Lisp |
Latendresse et al., 2012 |
|
ReactionDecoder |
Predicts the mapping of reactant to product atoms |
Java |
Rahman et al., 2016 |
|
ReactionMap |
Predicts the mapping of reactant to product atoms |
REST |
Fooshee et al., 2013 |
1.4.2. Modeling and simulation tools¶
Here, we review several advances in modeling and simulation technology that we believe are beginning to enable researchers to aggregate and organize the data needed for WC modeling and design, describe, simulate, calibrate, verify, and analyze WC models.
1.4.2.1. Data aggregation and organization tools¶
To make the large amount of publicly available data usable for modeling, researchers are developing tools such as BioServices [54] for programmatically accessing repositories and using PGDBs to organize the data needed for modeling. PGDBs are well-suited to organizing the data needed for WC models because they support structured representations of metabolites, DNA, RNA, proteins, and their interactions. However, traditional PGDBs provided limited support for non-metabolic pathways and quantitative data. Consequently, we are developing WholeCellKB, a PGDB specifically designed for WC modeling [30].
1.4.2.2. Model design tools¶
Several software tools have been developed for designing models of individual cellular pathways including BioUML [67], CellDesigner [68], COPASI [69], JDesigner [70], and Virtual Cell [71] which support dynamical modeling; RuleBender which supports rule-based modeling [72]; and COBRApy [73], FAME [74], and RAVEN [75] which support constraint-based metabolic modeling; and (Table 1.4).
Recently, researchers have developed several tools that support some of the features needed for WC modeling. This includes SEEK which helps researchers design models from data tables [76], Virtual Cell which helps researchers design models from KEGG pathways [71][56], MetaFlux which helps researchers design metabolic models from PGDBs [61], the Cell Collective [77] and JWS Online [78] which help researchers build models collaboratively, PySB which helps researchers design models programmatically [79], and semanticSBML [80] and SemGen [81] which help researchers merge models.
Tool |
URL |
Reference |
|---|---|---|
Data aggregation tools |
||
BioCatalogue |
Bhagat et al., 2010 |
|
BIOSERVICES |
Cokelaer et al., 2013 |
|
Data organization tools |
||
GMOD |
Papanicolaou and Heckel, 2010 |
|
Pathway Tools |
Karp et al., 2016 |
|
WholeCellKB |
Karr et al., 2013 |
|
Model design tools |
||
CellDesigner |
Matsuoka et al., 2014 |
|
COPASI |
Mendes et al., 2009 |
|
JWS Online |
Olivier and Snoep, 2004 |
|
MetaFlux |
Latendresse et al., 2012 |
|
PhysioDesigner |
Asai et al., 2012 |
|
RAVEN |
Agren et al., 2013 |
|
RuleBender |
Smith et al., 2012 |
|
VirtualCell |
Schaff et al., 2016 |
|
Model testing and verification tools |
||
biolab |
Clarke at al., 2008 |
|
MEMOTE |
||
SBML-to-PRISM |
||
Model description languages |
||
BioNetGen |
Harris et al., 2016 |
|
BioPAX |
Demir et al., 2010 |
|
CellML |
Cuellar et al., 2015 |
|
kappa |
Wilson-Kanamori et al., 2015 |
|
ML-Rules |
Maus et al., 2011 |
|
PySB |
Lopez et al., 2013 |
|
SBML |
Hucka et al., 2015 |
|
Simulation description languages |
||
SED-ML |
Waltemath et al., 2011 |
|
SESSL |
Ewald and Uhrmacher, 2014 |
|
Simulators |
||
cobrapy |
Ebrahim et al., 2013 |
|
COPASI |
Mendes et al., 2009 |
|
ECell |
Takahashi et al., 2003 |
|
Lattice Microbes |
Hallock et al., 2014 |
|
libRoadRunner |
Somogyi et al., 2015 |
|
NFSim |
Sneddon et al., 2011 |
|
VirtualCell |
Schaff et al., 2016 |
|
Simulation result formats |
||
HDF5 |
Folk et al., 2011 |
|
NuML |
Dada et al., 2017 |
|
SBRML |
Dada et al., 2010 |
|
Simulation result databases |
||
Bookshelf |
Vohra et al., 2010 |
|
Dynameomics |
van der Kamp et al., 2010 |
|
SEEK |
Wolstencroft et al., 2011 |
|
WholeCellSimDB |
Karr et al., 2014 |
|
Visualization tools |
||
Vega |
Satyanarayan et al., 2017 |
|
The Visualization Toolkit (VTK) |
Hanwell et al., 2015 |
|
WholeCellViz |
Lee et al., 2013 |
|
Workflow management tools |
||
Galaxy |
Walker et al., 2016 |
|
Taverna |
Wolstencroft et al., 2013 |
|
VizTrails |
Freire and Silva, 2012 |
|
However, none of these tools are well-suited to WC modeling because none of these tools support all of the features needed for WC modeling including programmatically designing models from large data sources such as PGDBs; collaboratively designing models over a web-based interface; designing composite, multi-algorithmic models; representing models in terms of rule patterns; and recording the data sources and assumptions used to build models.
1.4.2.3. Model selection tools¶
Several methods have also been developed to help researchers select among multiple potential models, including likelihood-based, Bayesian, and heuristic methods [82]. ABC-SysBio [83][84], ModelMage [85], and SYSBIONS [86] are some of the most advanced model selection tools. However, these tools only support deterministic dynamical models.
1.4.2.4. Model refinement tools¶
Several tools have been developed for refining models, including using physiological data to identify molecular gaps in metabolic models and using databases of molecular mechanisms to fill molecular gaps in metabolic models [87][88]. GapFind uses mixed integer linear programming to identify all of the metabolites that cannot be both produced and consumed in metabolic models, one type of molecular gap in metabolic models [89]. GapFill [89], OMNI [90], and SMILEY [91] use linear programming to identify the most parsimonious set of reactions from reaction databases such as KEGG [56] to fill molecular gaps in metabolic models. FastGapFill is one of the most efficient of these gap filling tools [92]. GrowMatch extends gap filling to find the most parsimonious set of reactions that not only fill molecular gaps in metabolic models, but also correct erroneous gene essentiality predictions [93]. ADOMETA [94], GAUGE [95], likelihood-based gap filling [96], MIRAGE [97], PathoLogic [98] and SEED [99] extend gap filling further by using sequence homology and other genomic data to identify the genes which most likely catalyze missing reactions in metabolic networks. However, these tools are only applicable to metabolic models.
1.4.2.5. Model formats¶
Several formats have been developed to represent cell models including formats such as CellML [100] that represent models as collections of variables and equations, formats such as SBML [101] that represent models as collections of species and reactions, and more abstract formats such as BioNetGen [102], Kappa [103], and ML-Rules [104] that represent models as collections of species and rule patterns.
The Systems Biology Markup Language (SBML) was developed in 2002 to represent dynamical models that can be simulated by integrating ordinary differential equations or using the stochastic simulation algorithm, as well as the semantic biological meaning of models. Recently, SBML has been extended to support a wide range of models through the development of several new packages. The flux balance constraints package supports constraint-based models, the qualitative models package supports logical models, the spatial processes package support spatial models that can be simulated by integrating PDEs, the multistate multicomponent species package supports rule-based model descriptions, and the hierarchical model composition package supports composite models. SBML is by far the most widely supported and commonly used format for representing cell models. For example, SBML is supported by COPASI [69], the most commonly used cell modeling software program and BioModels, the most commonly used cell model repository [105]. However, SBML creates verbose model descriptions, the multistate multicomponent species package only supports a few types of combinatorial complexity, SBML does not directly support multi-algorithmic models, and SBML cannot represent model provenance including the data sources and assumptions used to build models [106].
More recently, Faeder and others have developed BioNetGen [102] and other rule-based formats to efficiently describe the combinatorial complexity of protein-protein interactions. These formats enable researchers to describe models in terms of species and reaction patterns which can be evaluated to generate all of the individual species and reactions in a model. This abstraction helps researchers describe reactions directly in terms of their chemistry, describe large models concisely, and avoid errors in enumerating species and reactions. Models that are described in rule-based formats such as BioNetGen can be simulated either by enumerating all of the possible species and reactions and then simulating the expanded model via conventional deterministic or stochastic dynamical simulation methods, or via network-free simulation which iteratively discovers individual species and reactions during simulation [107]. BioNetGen is the most commonly used rule-based modeling format and NFsim is the most commonly used network-free simulator. However, BioNetGen only supports few types of combinatorial complexity, BioNetGen does not support composite or multi-algorithmic models, BioNetGen cannot represent the semantic biological meaning of models, and BioNetGen cannot represent model provenance.
1.4.2.6. Simulation algorithms¶
Several algorithms have been developed to simulate cells with a wide range of granularity including algorithms for integrating systems of ODEs and PDEs, stochastic simulation algorithms, algorithms for simulating logical networks and Petri nets, and hybrid algorithms for co-simulating models that are composed of mathematically-dissimilar submodels.
The most commonly used algorithms to simulate cell models include algorithms for integrating systems of ODEs. These algorithms are best suited to simulating well-characterized and well-mixed systems that involve large concentrations that are robust to stochastic fluctuations. These algorithms are poorly suited to simulating stochastic processes that involve small concentrations, as well as poorly characterized pathways with little kinetic data. Consequently, ODE integration algorithms are poorly suited for WC modeling.
Stochastic simulation algorithms such as the Stochastic Simulation Algorithm (SSA) or Gillespie’s Algorithm [108], newer, more efficient implementations of SSA such as the Gibson-Bruck method and RSSA-CR [109], and approximations of SSA such as tau leaping, are commonly used to simulate pathways that involve small concentrations that are susceptible stochastic variation. However, these algorithms are only suitable for dynamical models which require substantial kinetic data, they are computationally expensive, especially for models that include reactions that have high fluxes, and they are limited to models with small state spaces. Consequently, stochastic simulation algorithms are poorly suited for simulating WC models.
Network-free simulation algorithms are stochastic simulation algorithms for efficiently simulating rule-based models without enumerating every possible species and reaction prior to simulation and instead discovering the active species and reactions during simulation. Unlike traditional stochastic simulation algorithms, network-free simulation algorithms can represent large models that have combinatorially large or even infinite state spaces. Otherwise, network-free stochastic simulation algorithms have the same limitations as other stochastic simulation algorithms.
FBA is the second-most commonly used algorithm for simulating cell models. FBA predicts the steady-state flux of each metabolic reaction using detailed information about the stoichiometry and catalysis of each reaction, a small amount of quantitative data about the chemical composition of cells, a small amount of data about the exchange rate of each extracellular nutrient, and the assumption that metabolism has evolved to maximize the rate of cellular growth. However, FBA has limited ability to predict metabolite concentrations and temporal dynamics, and its assumptions are largely only applicable to microbial metabolism. Consequently, FBA is not well-suited to simulating entire cells.
Logical simulation algorithms are frequently used for coarse-grained simulations of transcriptional regulation and other pathways for which we have limited kinetic data. Logical simulations are computationally efficient because they are coarse-grained. However, logical simulation algorithms are poorly suited to WC modeling because they cannot generate detailed quantitative predictions, and therefore have limited utility for medicine and bioengineering.
Multi-algorithmic simulations are ideal for WC modeling because they can simulate models that include fine-grained representations of well-characterized pathways, as well as coarse-grained representations of poorly-characterized pathways. Takahashi et al. developed one of the first algorithms for co-simulating multiple mathematically-dissimilar submodels [3]. However, their algorithm is not well-suited to WC modeling because it does not support FBA or network-free simulation. Recently, we and others developed a multi-algorithm simulation meta-algorithm which supports ODE integration, conventional stochastic simulation, network-free stochastic simulation, FBA, and logical simulation [27]. However, our algorithm violates the arrow of time and is not scalable to large models.
1.4.2.7. Simulation experiment formats¶
The Minimum Information About a Simulation Experiment (MIASE) guidelines have been developed to establish the minimum metadata that should be provided about a simulation experiment to enable other researchers to reproduce and understand the simulation [2]. The Simulation Experiment Description Markup Language (SED-ML) [110] and the Simulation Experiment Specification via a Scala Layer (SESSL) [111] formats have been developed to represent simulation experiments. Both formats are capable of representing all of the model parameters and simulator arguments needed to simulate a model. However, both formats are limited to a small range of model formats and simulators. SED-ML is limited to models that are represented using XML-based formats such as SBML, and SESSL is currently limited to Java-based simulators. Consequently, neither is currently well-suited to WC modeling.
1.4.2.8. Simulation tools¶
Numerous tools have been developed to simulate cell models including the BioUML [67], Cell Collective [77], COBRApy [73], COPASI [69], E-Cell [112], FAME [74], iBioSim [113], libRoadRunner [114], JWS Online [78], NFsim [107], RAVEN [75], and Virtual Cell [71].
COPASI is the most commonly used simulation tool. COPASI supports several deterministic, stochastic, and hybrid deterministic/stochastic simulation algorithms. However, COPASI does not support network-free stochastic simulation, FBA, logical, or multi-algorithmic simulation and COPASI does not support high-performance parallel simulation of large models.
Virtual Cell supports several deterministic, stochastic, hybrid deterministic/stochastic, network-free, and spatial simulation algorithms. However, Virtual Cell does not support FBA or multi-algorithmic simulations and Virtual Cell does not support high-performance parallel simulation of large models.
COBRApy, FAME, and RAVEN support FBA of metabolic models. However, these packages provide no support for other types of models.
E-Cell is one of the only simulation programs that supports multi-algorithmic simulation. However, E-Cell does not support FBA or rule-based simulation, and E-Cell does not scale well to large models.
Several tools including cupSODA [115], cuTauLeaping [116], and Rensselaer’s Optimistic Simulation System (ROSS) [117] have been developed to simulate models in parallel. However, cupSODA only supports deterministic simulation, cuTauLeaping only supports network-based stochastic simulation, cupSODA and cuTauLeaping only support GPUs, and ROSS is a low-level, general-purpose framework for distributed CPU simulation.
1.4.2.9. Calibration tools¶
Accurate parameter values are essential for reliable predictions. Many methods have been developed to calibrate models by numerically optimizing the values of their parameters, including derivative-based initial value methods and stochastic multiple shooting methods [118].
Several complementary methods have also been developed to optimize computationally-expensive, high-dimensional functions, including surrogate modeling, distributed optimization, and automatic differentiation. Surrogate modeling, which is also referred to as function approximation, metamodeling, response surface modeling, and model emulation, promises to reduce the computational cost of numerical optimization by optimizing a computationally cheaper model which approximates the original model [119][120][121][122]. Surrogate modeling has been used in several fields including aerospace engineering [123], hydrology [124], and petroleum engineering [125]. However, further work is needed to develop methods for efficiently generating reduced surrogate WC models.
Distributed optimization is also a promising approach for optimizing computationally expensive functions. Distributed optimization uses multiple agents, each simultaneously employing the same algorithm on different regions, to quickly identify optima [126][127]. Furthermore, agents can cooperate by exchanging information. Distributed optimization has been used in several fields including aerospace and electrical engineering [128][129] and molecular dynamics [130].
Another promising approach for optimizing computationally expensive functions is automatic differentiation. Automatic differentiation is an efficient technique for analytically computing the derivative of a function [131]. Automatic differentiation can be used to make derivative-based optimization methods tractable in cases where finite difference calculations are prohibitively expensive. Automatic differentiation has been used to identify parameters in chemical engineering [132], biomechanics [133], and physiology [134].
Several software tools have also been developed for calibrating cell models [135][136][137][138][139]. Some of the most advanced model calibration tools include DAISY which can evaluate the identifiability of a model [140], ABC-SysBio which uses approximate Bayesian computation [83], saCeSS which supports distributed, collaborative optimization [141], and SBSI which supports several distributed optimization methods [142]. Some of the most popular modeling tools, including COPASI [69] and Virtual Cell [71], also provide model calibration tools. However, none of these tools support multi-algorithmic models. To efficiently calibrate WC models, we should combine numerical optimization methods with additional techniques such as reduced surrogate modeling, distributed computing, and automatic differentiation.
1.4.2.10. Verification tools¶
Several tools have been developed to verify cell models, including formal verification tools that seek to prove or refute mathematical properties of models and informal verification tools that help modelers organize and evaluate computational tests of models. BioLab [143] and PRISM [144] are formal tools for verifying BioNetGen-encoded and SBML-encoded models, respectively. Memote [145] and SciUnit [146] are unit testing frameworks for organizing computational tests of models. Continuous integration tools such as CircleCI [147] and Jenkins [148] can be used to regularly verify models each time they are modified and pushed to a version control system (VCS) such as Git [149].
1.4.2.11. Simulation results formats¶
HDF5 is an ideal format for storing simulation results [150]. In particular, HDF5 supports hierarchical data structures, HDF5 supports compression, HDF5 supports chunking to facilitate fast retrieval of small slices of large datasets, HDF5 can store both simulation results and their metadata, and there are HDF5 libraries available for several languages including C++, Java, MATLAB, Python, and R.
1.4.2.12. Simulation results databases¶
Several database systems have been developed to organize simulation results for visual and mathematical analysis and disseminate simulation results to the community [151][152][153][154][155][156][157]. We developed WholeCellSimDB, a hybrid relational/HDF5 database, to organize, search, and share WC simulation results [158]. WholeCellSimDB uses HDF5 to store simulation results and a relational database to store their metadata. This enables WholeCellSimDB to efficiently store simulation results, quickly search simulations by their metadata, and quickly retrieve slices of simulation results. WholeCellSimDB providers uses two interfaces to deposit simulation results; a web-based interface to search, browse, and visualize simulation results; and a JSON web service to retrieve simulation results. However, further work is needed to scale WholeCellSimDB to larger models and to develop tools for quickly searching WholeCellSimDB.
1.4.2.13. Simulation results analysis¶
Several tools have been developed to analyze and visualize simulation results. The most popular simulation software programs, including COPASI [69], E-Cell [112], and Virtual Cell [71], provide basic tools for visualizing simulation results. Tools such as Escher [159] and Pathway Tools Omics Viewer [160] can also be used to visualize simulation results.
We developed WholeCellViz to visualize WC simulation results in their biological context [161]. WholeCellViz provides users time series plots and interactive animations to visualize model predictions, and enables users to arrange grids of plots and animations to help users compare predictions across multiple simulation runs and simulated conditions. However, further work is needed to scale WholeCellViz to larger models and to make it easier to incorporate new visualizations into WholeCellViz.
1.4.3. Models of individual pathways and model repositories¶
Since the 1950’s, researchers have been using the tools described above to model cells. This has led to numerous models that represent individual pathways. Here, we review our progress in modeling individual pathways, building repositories of cell models, and their utility for WC modeling.
1.4.3.1. Models of individual pathways¶
Over the past 30 years, researchers have developed a wide range of models of individual cellular pathways [105] (Figure 1.4, Table 1.5). In particular, researchers have developed models of cell cycle regulation [162]; circadian rhythms [163]; electrical signaling [164]; metabolism [165][166][167]; signaling pathways such as the JAK/STAT, NF-\(\kappa\)B, p53, and TGF\(\beta\) pathways [168]; transcriptional regulation [169], and multicellular processes such as developmental patterning [170] and infection. However, many pathways have not been modeled at the scale of entire cells, including several well-studied pathways. For example, although we have extensive knowledge of the mutations responsible for cancer, we have few models of DNA repair; although we have extensive structural and catalytic information about RNA modification, we have few kinetic models of RNA modification; and although we have detailed atomistic models of protein folding, we have few cell-scale models of chaperone-mediated folding.
Figure 1.4 WC models can be built by leveraging existing models of well-studied processes (colors) and developing new models of other processes (gray).¶
Number of models in BioModels, by kingdom |
Mean model size |
|||||||
|---|---|---|---|---|---|---|---|---|
Pathway |
Formalisms |
Viruses |
Eukaryotes |
Bacteria |
Unannotated |
Species |
Reactions |
Parameters |
Cell cycle |
ODEs, SSA |
44 |
14.0 |
19.4 |
33.6 |
|||
Cell death |
ODEs |
11 |
2 |
24.5 |
33.6 |
42.2 |
||
Circadian regulation |
ODEs |
38 |
1 |
17.3 |
31.2 |
65.5 |
||
DNA repair |
ODEs |
1 |
23.0 |
25.0 |
26.0 |
|||
Electrical signaling |
ODEs |
34 |
5 |
12.7 |
26.4 |
37.5 |
||
Gene expression regulation |
Boolean network |
9 |
10 |
5 |
11.9 |
14.0 |
15.5 |
|
Host-pathogen interaction |
ODEs |
1 |
2 |
1 |
24.3 |
44.5 |
58.0 |
|
Intracellular transport |
ODEs |
2 |
2 |
7.8 |
12.8 |
16.3 |
||
Macromolecule modification |
ODEs |
1 |
2 |
10.7 |
26.0 |
19.7 |
||
Metabolism |
FBA, ODEs |
100 |
16 |
5 |
57.0 |
39.7 |
195.6 |
|
Motility |
ODEs, PDEs |
2 |
2 |
40.8 |
48.3 |
79.5 |
||
Organismal process |
ODEs |
1 |
66 |
2 |
2 |
17.2 |
20.1 |
48.8 |
Regulation, other |
ODEs |
5 |
14 |
12.0 |
17.8 |
22.2 |
||
Signal transduction |
ODEs, SSA |
144 |
3 |
30 |
35.3 |
54.1 |
67.8 |
|
Stress response |
ODEs |
9 |
16.6 |
19.4 |
46.2 |
|||
Collectively, these models span a broad range of scales. For example, although most of these models represent the chemical transformations responsible for each pathway, some of these models, such as most transcriptional regulation models, use coarser representations. As a second example, although most of these models represent temporal dynamics, most metabolic models only represent the steady-state behavior of metabolism [13]. Similarly, although most of these models represent cells as well-mixed bags, some of these models represent the spatial distribution of individual compounds including nutrients and hormones [171][172][173]. In addition, although most of these models represent the mean behavior of cells, averaged over multiple cells and cell cycle phases, a few of these models represent the temporal dynamics of the cell cycle and the variation among single cells.
Collectively, these models also use a wide range of computational representations and simulation algorithms. Many of these models are represented as reaction networks. However, some of the largest of these models must be represented using rules [102] or Boolean networks. Many of these models can be simulated by integrating ODEs. However, some of the largest models must be simulated using network-free methods [107], the steady-state metabolism models must be simulated with FBA [13], some of the spatiotemporal models must be simulated by integrating PDEs, and some of the network models must be simulated by iteratively evaluating Boolean regulatory functions [174].
These pathway models could be used to help build WC models. However, substantial work would be required to integrate these models into a single model because these models describe different scales, make different assumptions, are represented using different mathematical formalisms, are calibrated to different organisms and conditions, and are represented using different identifiers and formats. To avoid needing to substantially revise pathway models for incorporation into WC models, modelers should build pathway models explicitly for integration into WC models. This requires the modeling community to embrace a common format, common identifiers, common units, and common standards for model calibration and validation.
1.4.4. Models of multiple pathways¶
Since 1999 when Tomita et al. reported one of the first models of multiple pathways of M. genitalium [17], researchers have been trying to build increasingly comprehensive models of multiple pathways. In particular, this has led to models of Escherichia coli and Saccharomyces cerevisiae which describe their metabolism and transcriptional regulation [18][19]; their metabolism, signaling, and transcriptional regulation [20][21][22]; and their metabolism and RNA and protein synthesis and degradation [23]. Table 1.6 summarizes several recently published and proposed models of multiple pathways. Despite this progress, these models only represent a small number of pathways and a small number of organisms.
Pathways |
Computational representation |
Species |
Status |
References |
|
|---|---|---|---|---|---|
28 |
Chromosome Condensation, Chromosome Segregation, Cytokinesis, DNA damage, DNA repair, DNA supercoiling, FtsZ Polymerization, Host interaction, Macromolecular complexation, Metabolism, Protein activation, Protein decay, Protein folding, Protein modification, Protein processing I, Protein processing II, Protein translocation, Replication, Replication Initiation, Ribosome assembly, RNA decay, RNA modification, RNA processing, Terminal organelle assembly, Transcription, Transcriptional regulation, Translation, tRNA aminoacylation |
Hybrid: Boolean, flux balance analysis, ordinary differential equations, stochastic simulation |
Mycoplasma genitalium |
Published |
Karr et al., 2012 |
6 |
Metabolism, protein complexation, RNA maturation, RNA modification, transcription, translation |
Flux balance analysis |
Escherichia coli |
Published |
Thiele et al., 2009 |
5 |
Metabolism, protein degradation, RNA degradation, transcription, translation |
Ordinary differential equations |
Mycoplasma genitalium |
Published |
Tomita et al., 1999 |
3 |
Circadian rhythms, metabolism, transcriptional regulation |
Hybrid: flux balance analysis, ordinary differential equations |
Synechocystis sp. PCC 6803 |
Proposed |
Steuer et al., 2012 |
3 |
Contraction, electrical signling, metabolism |
Ordinary differential equations |
Homo sapiens |
Proposed |
Bassingthwaighte et al., 2005 |
3 |
Metabolism, signal transduction, transcriptional regulation |
Hybrid: Boolean, flux balance analysis, ordinary differential equations |
Escherichia coli |
Published |
Covert et al., 2008 |
3 |
Metabolism, signal transduction, transcriptional regulation |
Hybrid: constraint-based modeling, ordinary differential equations, phenomenological modeling |
Escherichia coli |
Published |
Carrera et al., 2014 |
3 |
Metabolism, signal transduction, transcriptional regulation |
Ordinary differential equations |
Saccharomyces cerevisiae |
Published |
Klipp et al., 2005 |
3 |
Metabolism, signal transduction, transcriptional regulation |
Hybrid: Boolean, flux balance analysis, ordinary differential equations |
Saccharomyces cerevisiae |
Published |
Lee et al., 2008 |
3 |
Metabolism, signal transduction, transcriptional regulation |
Hybrid: Boolean, flux balance analysis, ordinary differential equations |
N/A |
Review |
Gonçalves et al., 2013 |
2 |
Cell cycle regulation, metabolism |
Hybrid: Flux balance analysis, ordinary differential equations |
Saccharomyces cerevisiae |
Proposed |
Barberis et al., 2017 |
2 |
Cell cycle regulation, signal transduction |
Logical model |
Homo sapiens |
Published |
Huard et al., 2012 |
2 |
Contraction, electrical signling |
Ordinary differential equations |
Homo sapiens |
Published |
Greenstein et al., 2006 |
2 |
Metabolism, signal transduction |
Ordinary differential equations |
Homo sapiens |
Published |
König et al., 2012 |
2 |
Metabolism, signal transduction |
Ordinary differential equations |
Homo sapiens |
Published |
Mosca et al., 2012 |
2 |
Metabolism, transcriptional regulation |
Hybrid: Boolean, flux balance analysis |
Escherichia coli |
Published |
Covert et al., 2004 |
2 |
Metabolism, transcriptional regulation |
Hybrid: Bayesian, flux balance analysis |
Escherichia coli |
Published |
Chandrasekaran and Price, 2010 |
2 |
Metabolism, transcriptional regulation |
Hybrid: Boolean, flux balance analysis |
Escherichia coli |
Published |
Shlomi et al., 2007 |
2 |
Electrical signaling, tension development |
Ordinary differential equations |
Homo sapiens |
Published |
Niederer and Smith, 2007 |
2 |
Signal transduction, transcriptional regulation |
Ordinary differential equations |
Homo sapiens |
Published |
Nakakuki et al., 2010 |
2 |
Signal transduction, transcriptional regulation |
Ordinary differential equations |
Homo sapiens |
Published |
Stelniec-Klotz et al., 2012 |
2 |
Metabolism, transcriptional regulation |
Hybrid: Bayesian, flux balance analysis |
Mycobacterium tuberculosis |
Published |
Chandrasekaran and Price, 2010 |
2 |
Metabolism, transcriptional regulation |
Hybrid: Bayesian, flux balance analysis |
Mycobacterium tuberculosis |
Published |
Ma et al., 2015 |
To represent multiple pathways, most of these models have been developed by combining separate submodels of each pathway, using the most appropriate mathematical representation for each pathway. This has led to multi-algorithmic models which must be simulated by co-simulating the individual submodels. Because there are few multi-algorithmic simulation tools and most of these models only combine two or three submodels, the developers of most of these models have developed ad hoc methods to simulate their models. For example, Covert et al. developed an ad hoc method to simulate their hybrid dynamic FBA / Boolean model of the metabolism and transcriptional regulation of E. coli [18] and Chandrasekaran and Price developed a different ad hoc method to simulate their hybrid FBA / Bayesian model of the metabolism and transcriptional regulation of E. coli [19]. Because there are few tools for working with such integrative models, these models have also been described with different ad hoc formats and identifiers, simulated with different ad hoc simulation software programs, and calibrated and validated with different ad hoc methods.
1.4.4.1. Model repositories¶
Several model repositories, including BioModels [105] and the Physiome Model Repository [175], have been developed to make it easy to find models (Table 1.7). However, only a few of these repositories support integrated models; most of these repositories only support a limited number of model formats; many reported models are never deposited to any model repository; many of the models that are deposited are not sufficiently annotated for other researchers to understand, reuse, and extend the models; and only a few of the repositories also support the information needed to simulate models such as parameter values.
Repository |
Content |
URL |
Reference |
|---|---|---|---|
BiGG |
Repository for constraint-based models of metabolism |
King et al., 2016 |
|
BioModels |
Repository for SBML-encoded models that contains many cell cycle, circadian, electrical signaling, metabolism, and signal transduction models |
Chelliah et al., 2015 |
|
FigShare |
Repository for supplemental materials that contains some models |
||
GitHub |
Repository for code that contains some models |
||
JWS Online |
Online environment for systems biology modeling that includes a model repository |
Peters et al., 2017 |
|
Open Source Brain |
Repository for NeuroML-encoded models of neurophysiology |
Gleeson et al., 2012 |
|
Physisome Repository |
Repository for CellML-encoded models that contains physiological models |
Yu et al., 2011 |
|
SimTK |
Repository for data and code that contains several biomechanics models |
1.5. Emerging principles and methods for WC modeling¶
In the previous section, we outlined the ongoing technological advances that are making WC modeling feasible. Here, we propose several principles for WC modeling and describe how we and others are adapting and integrating these technologies into a methodology for WC modeling. In the following sections, we outline the major remaining bottlenecks to WC modeling, highlight ongoing efforts to overcome these bottlenecks, and describe how we are beginning to use this methodology to build WC models.
1.5.1. Principles of WC modeling¶
Based on our experience, we propose several guiding principles for WC modeling (Figure 1.5).
Modular modeling. Similar to other large engineered systems such as software, WC models should be built by partitioning cells into pathways, outlining the interfaces among these pathways, building submodels of each pathway, and combining these submodels into a single model. This approach reduces the dimensionality of model construction, calibration, and validation and facilitates collaborative modeling.
Multi-algorithmic simulation. Furthermore, to capture both well- and poorly-characterized pathways, each pathway should be represented using the most appropriate mathematical representation given our knowledge and data about each pathway. In particular, multi-algorithmic simulation should be used to create identifiable models which can be calibrated from our experimental data.
Experimental calibration and validation. WC models should be rigorously calibrated and extensively validated via comparison to detailed experimental data across a wide range of molecular mechanisms, phenotypes, and scales.
Systemization and standards. To scale modeling to entire cells and facilitate collaboration, we should systemize every aspect of dynamical modeling, develop standards for describing WC models and standard protocols for validating and merging model components, and encourage researchers to embrace these standard protocols and formats.
Technology development. To enable WC modeling, we must develop technologies for systematically and scalably building, calibrating, simulating, and validating WC models. These technologies should be modular to facilitate collaborative technology development and integrated into a unified framework to provide modelers user-friendly modeling and simulation tools.
Leverage existing methods and data. Where possible, WC modeling should take advantage of existing computational methods and experimental data. For example, WC modeling should take advantage of parallel simulation methods developed by computer science and WC models should be built, in large part, from data aggregated from public repositories.
Focus on critical problems and clear, achievable goals. To maximize our efforts, we should periodically identify the key bottlenecks to WC modeling and periodically refocus our efforts on overcoming these bottlenecks. Based on lessons learned from other “big science” projects [176][177], we should also delineate clear goals and clearly define the responsibilities of each researcher.
Focus on model organisms. To facilitate collaboration, early WC modeling efforts should focus on a small number of organisms and cell lines that are easy to culture, well-characterized, karyotypically and phenotypically “normal”, genomically stable and relevant to a wide range of basic science, medicine, and bioengineering. This includes well-characterized bacteria such as Escherichia coli and well-characterized human cell lines such as the H1 human embryonic stem cell (hESC) line.
Reproducibility, transparency, extensibility, and openness. To facilitate collaboration and maximize impact, WC models and simulations should be reproducible, comprehensible, and extensible. For example, to enable other modelers to understand a model, the biological semantic meaning of each species and reaction should be annotated, the data sources and assumptions used to design the model should be annotated, and the parameter values used to produce each simulation result should be recorded. Furthermore, each WC model and WC modeling technology should be free and open-source.
Constant innovation. Because we do not yet know exactly what WC models should represent, what WC models should predict, or how to build WC models, we should periodically evaluate the quality of our models and methods and iteratively improve our models and methods as we learn more about cell biology and WC modeling. This should include how we partition cells into pathways, the interfaces that we define among the pathways, and how we simulate multi-algorithmic models.
Interdisciplinary collaboration. WC modeling should be an interdisciplinary collaboration among modelers, experimentalists, computer scientists, and engineers, and research sponsors. Furthermore, there should be open and frequent communication among the WC modeling community.
Figure 1.5 Principles of WC modeling.¶
1.5.2. Methods for WC modeling¶
To enable WC models, we and others are adapting and integrating the technologies described in Section 1.4.2 into a workflow for scalably building, simulating, and validating WC models (Figure 1.6). (1) Modelers will use Datanator to aggregate, standardize, and integrate the experimental data that they will need to build, calibrate, and validate their model into a single dataset. (2) Modelers will use this data to design submodels of each individual pathway using the most appropriate mathematical representation for each pathway, and encode their model in wc_rules, a rule-based format for describing WC models. (3) Modelers will construct reduced models, and use them to calibrate each submodel and their entire model. (4) Modelers will use formal verification and/or unit testing to verify that their model functions as intended and recapitulates the data used to build the model. (5) Modelers will use wc_sim, a scalable, network-free, multi-algorithmic simulator, to simulate their model. (6) Modelers will use WholeCellSimDB to organize their simulation results and use WholeCellViz to visually analyze these results. Importantly, every tool in this workflow will facilitate collaboration to help researchers work together, and these tools will be modular to enable us and others to continuously improve this methodology. We plan to implement this workflow by leveraging recent advances in computational and experimental technology (Section 1.4). Here, we describe the six steps of this emerging workflow.

Figure 1.6 Emerging workflow for scalably building, simulating, and validating WC models. (a) Modelers will aggregate the data for WC modeling into a single dataset. (b) Modelers will use this data to design multi-algorithmic WC models. (c,d) Modelers will use reduced models to calibrate, verify, and validate models. (e) Modelers will simulate multi-algorithmic WC models by co-simulating their submodels. (f) Modelers will visualize and analyze their results to discover new biology, personalize medicine, and design microorganisms.¶
1.5.2.1. Data aggregation, standardization, and integration¶
The first step of WC modeling is to aggregate, standardize, integrate, and select the experimental data needed for WC modeling into a single dataset for model building, calibration, and validation (Figure 1.6a).
First, we must aggregate a wide range of experimental data from a wide range of databases such as such as biochemical data about metabolite concentrations from ECMDB [47], RNA-seq data about RNA concentrations from ArrayExpress [31], and mass-spectrometry data about metabolite concentrations from PaxDb [33]. Where possible, data should be aggregated using database downloads and web services. Otherwise, data should be aggregated by scraping webpages. In addition to aggregating data from databases, we should also aggregate data from collaborators, individual publications, and bioinformatics prediction tools such as PSORTb [65] and TargetScan [66].
To the extent possible, we should record the provenance of this data including the biosample (e.g., species, strain, genetic variants) and environmental conditions (e.g., temperature, pH, growth media) that were measured, the experimental method used to generate the data, the computational method used to analyze the data, and the citation for original data to help us select the most relevant data for modeling and trace models back to their data sources.
Second, we must standardize the identifiers and units used to describe this data. For example, metabolites should be identified using the IUPAC International Chemical Identifier (InChI) format [178] and RNA should be identified by their genomic coordinates. Similarly, all units should be standardized to SI units or combinations of SI units.
Third, we must integrate this data by linking the data together through common metabolites, chromosomes, RNA, proteins, and interactions. To enable this data to be quickly searched and explored, this data should be organized into a relational database.
Fourth, we must identify the most relevant data within our database for the species and environmental condition that we want to model. For each experimental measurement that we need to constrain a model, we must search our database for data observed for similar biology (e.g., metabolites, RNA, proteins, and interactions), genotypes (e.g., species, strain, and genetic variants), and environmental conditions (e.g., temperature, pH, growth media); calculate the relevance of each experimental observation; and calculate the consensus of the relevant observations, weighted by their relevance.
Fifth, we should organize these consensus experimental values and their provenance (experimental evidence and the method used to calculate the consensus value) into a single dataset. Pathway/genome databases (PGDB) can be used to organize this information because PGDBs are well-suited to representing relationships among experimental data about a single species. We have developed the WholeCellKB PGDB to organize the data needed for WC modeling. WholeCellKB provides users three interfaces to deposit experimental data for WC models, extensive functionality for validating this data, a web-based user interface to search and browse this data, and a JSON web service to programmatically retrieve data for model construction.
1.5.2.2. Model design¶
The second step of WC modeling is to use the data aggregated in the first step to design models, including each species and interaction (Figure 1.6b). To represent the details of well-characterized pathways, as well as coarsely represent poorly-characterized pathways, WC models should be built by partitioning cells into pathways, modeling each pathway using the most appropriate mathematical representation, and combining pathway submodels into composite, multi-algorithmic models.
To capture the large number of possible cellular phenotypes, WC models should also capture the combinatorial complexity of cellular biochemistry. For example, WC models should represent the combinatorial number of RNA transcripts that can be produced from the interactions of transcription, RNA editing, RNA folding, and RNA degradation; WC models should represent the combinatorial number of possible interactions among the subunits of protein complexes; and the combinatorial number of phosphorylation states of each protein complex.
To generate accurate predictions, WC models should also aim to represent the aggregate physiology of poorly understood biology such as uncharacterized genes, uncharacterized small peptides, and uncharacterized non-coding RNA. This can be accomplished by including lumped reactions that represent the aggregate physiology of all unknown biology. For example, to accurately predict metabolic reaction fluxes, like FBA models, WC models can include reactions that capture the aggregate energy usage of all uncharacterized interactions.
To scalably and reproducibly build WC models, WC models should be programmatically built from PGDBs using scripting tools such as PySB [79].
Because WC models will never be complete, WC models should be built by designing an initial model and then iteratively improving the model until the model accurately predicts new experimental measurements. In particular, WC models can be systematically refined by identifying gaps between their bottom-up descriptions of cellular biochemistry and our physiological knowledge, searching for reactions and gene products that might fill those gaps, and parsimoniously adding species and reactions to models so they recapitulate experimental observations. Model selection methods can also be used to select among multiple potential model designs. Furthermore, version control systems such as Git [149] should be used to track model changes and enable collaborators to refine models in parallel and merge their refined models.
To enable other researchers to reproduce, understand, reuse, and extend WC models, WC models should be encoded in rule-based formats such as BioNetGen and extensively annotated. In particular, rule-based formats enable researchers to concisely describe the combinatorial complexity of cell biology. Model annotations should include semantic annotations about the biological meaning of each species and interaction such as the chemical structure of each metabolite in InChI format [178] and provenance annotations about the data sources, assumptions, and design decisions behind each species, interaction, and pathway.
1.5.2.3. Model calibration¶
The third step in WC modeling is to calibrate model parameters (Figure 1.6c). This should be done by using numerical optimization methods to minimize the distance between the model’s predictions and related experimental observations. One promising method for calibrating composite WC models is to (a) use multi-algorithmic modeling to only create parameters whose values can be constrained by one or a small number of experimental measurements, (b) estimate the value of each individual parameter using one or a small number of experimental observations, (c) construct a set of reduced models, one for each submodel, to estimate the joint values of the parameters, and (d) use distributed global optimization tools such as saCeSS [141] to refine the joint values of the parameters [179]. This method avoids the need to calibrate large numbers of parameters of physiological data; performs the majority of model calibration using low dimensional models of individual species, reactions, and pathways; and generates successively better starting points for more refined calibration.
1.5.2.4. Model verification and validation¶
The fourth step in WC modeling is to verify that models behave as intended and validate that models recapitulate the true biology (Figure 1.6d). First, WC should be verified models using a series of increasingly comprehensive unit tests that test each individual species, reaction, and pathway, as well as groups of pathways and entire models. Importantly, these tests should cover all of the logic of the model. For example, these tests should test the edge cases of every rate law. Reduced models should be used to efficiently test individual species, reactions, and pathway submodels. Furthermore, to quickly identify errors, continuous integration systems such as Jenkins [148] should be used to automatically execute tests each time models are revised. Alternatively, models can be verified using formal verification systems such as PRISM [144]. However, substantial work remains to adapt formal verification to multi-algorithmic dynamical modeling.
Second, WC models should be validated by comparing their simulation results to independent experimental data that was not used for model construction or calibration. To be effective, models should be tested using a broad range of data that spans different types of predictions, genetic perturbations, and environmental conditions.
Third, because it is infeasible to validate possible model prediction, modelers should annotate how models were validated to help other modelers know which model predictions can be trusted, know which predictions still need to be validated, and reuse the validation data to validate improved and/or extended models. These annotations should include which data were used for validation, which predictions were validated, and how well the model recapitulated each experimental observation. We believe that this metadata will be critical for medicine where therapy should only be driven by validated model predictions.
1.5.2.5. Network-free multi-algorithmic simulation¶
The fifth step of WC modeling is to numerically simulate WC models (Figure 1.6e). Because WC models should be described using rules and composed of multiple mathematically-dissimilar submodels, WC models simulated by co-simulating their submodels. This can be achieved in three steps. First, all of the submodels should be converted to explicit time-driven submodels. For example, Boolean submodels should be converted to SSA submodels by assuming typical concentrations and kinetic rates. Second, all of the mathematically-similar submodels should be analytically merged into a single mathematically-equivalent submodel. Third, for WC models that are composed only of FBA, ODE, and ODE submodels, (a) the SSA submodel should be used as the master clock for the integration and synchronization of the submodels, (b) each time the SSA submodel advances to the next iteration, the FBA and ODE submodels should be synchronized with the SSA submodel and integrated for the same timestep as the SSA submodel, (c) and the SSA submodel should be synchronized with the FBA and ODE models. If the FBA or ODE models generate unphysical states such as negative concentrations, they must be rolled back and reintegrated for multiple smaller timesteps. To efficiently simulate WC models, the FBA and ODE models should only be evaluated periodically.
To efficiently simulate the combinatorial complexity represented by WC models, most submodels should be simulated using SSA and SSA should be implemented using network-free graph-based methods. Specifically, SSA should be implemented by representing each molecule as a graph, representing each reaction rule as a graph, searching for matching pairs of species-reaction graphs to determine the rate of each reaction, randomly selecting a reaction to fire, updating the species involved in the selected reaction, and using a species-reaction dependency graph to update the rates of all affected reactions. This methodology will enable WC simulations to scale to large numbers of possible species and reactions by only representing the configuration of each active molecule rather than representing the copy number of each possible species.
To simulate WC models quickly, WC models should be simulated using a distributed simulation framework such as parallel discrete event simulation (PDES) and partitioning WC models into cliques of tightly connected species and reactions.
To make WC simulations comprehensible and reproducible, WC simulations should be represented using a common format such as SED-ML or SESSL.
1.5.2.6. Visualization and analysis of simulation results¶
The sixth step of WC modeling is to visualize and analyze WC simulation results to discover new biology, personalize medicine, or design microbial genomes (Figure 1.6f). First, all of the metadata needed to understand and reproduce simulation results should be recorded, including the model, the version of the model, the parameter values, and the random number generator seed that was simulated. Second, simulation results should be logged and stored in HDF5 format [150]. Third, WC simulation results and their metadata should be organized using a tool such as WholeCellSimDB that helps researchers search, slice, reduce, and share simulation results. Fourth, researchers should use tools such as WholeCellViz to visually analyze WC simulation results and use visualization grammars such as Vega [180] to develop custom diagrams.
1.6. Latest WC models and their limitations¶
Because it is not yet possible to completely model a cell, researchers are pursuing several complementary approaches to modeling entire cells. Historically, researchers such as Michael Shuler focused on building coarse-grained models of the major functions of cells [25][181]. Over the last ten years, researchers have begun to leverage the growing wealth of experimental data and our increasing computational power to build fine-grained models of the molecular biology of entire cells. This includes bottom-up efforts to represent the contribution of each gene to cellular behavior starting from genome sequences and annotations [27], top-down efforts to represent the integrated behavior of each cellular process, and bottom-up efforts to model diffusion at the cell scale [182][183][26]. More recently, researchers have begun to merge these fine-grained approaches. For example, Schulten recently demonstrated a hybrid FBA-diffusion model of E. coli [184]. Here, we describe recent progress in each of these major approaches to WC modeling.
1.6.1. Coarse-grained models¶
In adddition fine-grained models, researchers have also developed several coarse-grained models of multiple cellular processes [25][181]. These models could be used to help inform the global structure and mathematical behavior of WC models. However, they generally cannot be directly incorporated into WC models because they use coarse-grained representations that are incompatible with that of fine-grained WC models.
1.6.2. Genomically-centric bottom-up fine-grained models¶
Toward WC models, recently, we and others demonstrated the first model which represents every characterized gene function of a cell [27] (Figure 1.7a). The model represents 28 pathways of M. genitalium. The model was developed by annotating the M. genitalium genome, reconstructing the species encoded by each gene and the reactions catalyzed by each gene using data from over 900 databases and publications, partitioning the species and reactions into 28 pathways, developing separate submodels of each pathway, and integrating the submodels into a single model. To help us organize the data used to build the model, we developed WholeCellKB, a pathway/genome database (PGDB) software system tailored for WC modeling [30], and developed scripts to generate the model from the PGDB.
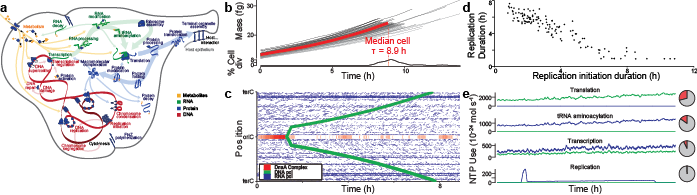
Figure 1.7 A WC model of M. genitalium predicts high-level cellular behaviors from the molecular level. (a) The model combines multiple submodels of individual cellular subsystems. We validated the model by comparing its outputs to experimental data which describes its rate of growth (b) and RNA polymerase occupancy (c). We have used the model to understand how cells regulate their cell cycle (d) and allocate energy (e).¶
To capture our varying level of knowledge about each pathway, we described each pathway using the most appropriate mathematical representation. For example, we represented transcription and translation as stochastic models, represented metabolism using FBA, and represented cell division with ODEs. We combined the submodels into a single model by mapping their inputs and outputs onto a common set of global variables that we formed by taking the union of the state variables of the individual submodels.
We developed a novel algorithm to simulate the combined model by co-simulating the submodels. The algorithm co-simulated the submodels by partitioning the copy number variables into separate pools for each submodel proportional to their anticipated consumption, iteratively integrating the submodels, updating the global variables by merging the pools associated with the submodels, and updating all other state variables. To help us analyze the model’s simulation results, we also developed WholeCellSimDB, a database for organizing, storing, and sharing WC simulation results [158] and WholecellViz, a web-based software tool for visualizing high-dimensional WC simulation results in their biological context [161].
We calibrated the model by constructing a set of reduced models that focused on each pathway submodel, calibrating the individual submodels, and using the parameter values learn from calibrating the individual submodels as a starting point for calibrating the entire model [179].
We validated the model by constructing numerous reduced models that focused on individual submodels and groups of submodels, checking that the submodels and groups of submodels are consistent with our knowledge such as the Central Dogma, and checking that the submodels and groups of submodels are consistent with the experimental data that we used to build the model and additional independent experimental data (Figure 1.7b,c). In particular, we demonstrated that the model recapitulates the observed M. genitalium growth rate and predicts the essentiality of each gene with 80% accuracy.
In addition, we have used the model to demonstrate how WC models could be used to help design synthetic circuits [185] and we have used the model to demonstrate how WC models could help reposition antibiotics among distance bacteria [186].
Despite this progress, the model does not represent several important cell functions such as the maintenance of electrochemical gradients across the cell membrane, and the model mispredicts several important phenotypes such as the growth rates of many single-gene deletion strains. Furthermore, the model took over 10 person-years to construct because it was largely built by hand; the model is difficult to understand, reuse, and extend because it was described directly in terms of its numerical simulation rather than using a high-level format such as SBML; the model’s simulation software is not reusable because it was built to simulate a single model; the model’s simulation algorithm violates the arrow of time and is unscalable because it only partitions a portions of the state variables among the submodels.
1.6.3. Physiologically-centric top-down fine-grained models¶
In parallel, researchers such as Edda Klipp are taking a complementary top-down physiologically-centric approach to WC modeling to our genomically-centric bottom-up approach to WC modeling. In contrast to our approach which starts from annotated genomes, Edda Klipp and her colleagues are modeling entire cells by enumerating the major processes present in cells, developing submodels of each process, and combining the submodels into a single model.
1.6.4. Spatially-centric bottom-up fine-grained models¶
In parallel, researchers such as Elijah Roberts and Zaida Luthy-Schulten are taking another complementary spatially-centric approach to WC modeling [182][183][26]. This approach focuses on representing the spatial distribution and diffusion of each molecular species, and uses molecular dynamics simulation methods to predict their spatiotemporal dynamics. However, because it is computationally expensive to simulate diffusion on the scale of entire cells, this approach is currently limited to second-scale simulations.
1.7. Bottlenecks to more comprehensive and predictive WC models¶
In the previous sections, we described how we and others are beginning to build WC models. Despite this progress, it is still challenging to build and simulate WC models. To help focus the community’s efforts to accelerate WC modeling, here, we summarize the major remaining bottlenecks to WC modeling (Figure 1.8). These bottlenecks are based on our own experience and a community survey of the bottlenecks to biomodeling that we conducted in 2017 [16]. In the following sections, we suggest ways to overcome these bottlenecks.

Figure 1.8 Major bottlenecks to WC modeling and the major methods, tools, and resources needed to advance WC modeling.¶
1.7.1. Inadequate experimental methods and data repositories¶
In our opinion, one of the biggest bottlenecks to WC modeling is collecting and aggregating enough high-quality experimental data to build WC models. This is a significant bottleneck because WC models require extensive data, and because, as described in Section 1.3.1, we do not yet have sufficient methods for characterizing cells, sufficient tools for annotating the semantic meaning of experimental data, sufficient repositories for aggregating and integrating experimental data, and sufficient incentives for researchers to share their data.
New measurement methods, data repositories, and data aggregation tools are needed to overcome this bottleneck: (a) improved proteome-wide methods for measuring protein abundances would facilitate more accurate models of many pathways; (b) improved metabolome-wide methods for measuring metabolite concentrations would enable more accurate models of metabolism; (c) new single-cell measurement methods would facilitate more accurate models of the phenotypic variation of single cells; (d) a new central data repository that uses consistent representations, identifiers, and units would accelerate data aggregation [187]; and (e) new tools for searching this repository would help researchers identify relevant data for WC modeling, including data from related organisms and environments.
1.7.2. Incomplete, inconsistent, scattered, and poorly annotated pathway models¶
As discussed in Section 1.5, the most promising strategy for building WC models is to combine multiple separate models. However, the lack of a complete set of compatible, well-annotated, and high-quality pathway models is a major bottleneck to WC modeling [80][81][188][24]. Here, we summarize the limitations of our pathway models.
1.7.2.1. Incomplete models¶
Despite decades of modeling research and detailed models of several pathways, we still do not have models of most pathways. For example, we do not have models of the numerous DNA repair mechanisms, the mechanisms responsible for RNA editing, or the role of chaperones in protein folding.
1.7.2.2. Poorly validated and unreliable models¶
Many of our existing pathway models are insufficiently validated and reliable to be effective components of WC models. Furthermore, few models are published with sufficient information about what data was used to validate the model, which simulation predictions were validated, and which simulation predictions are reliable for other researchers to know the limitations of a model and how to properly reuse it.
1.7.2.3. Inconsistent models¶
Furthermore, many of our existing pathway models are inconsistent. In particular, many of existing models are described with different assumptions, granularities, mathematical representations, identifiers, units, and formats.
1.7.2.4. Unpublished and scattered models¶
Unfortunately, our published models are scattered across a large number of resources, including model repositories such as BioModels, Simtk, supplementary materials, GitHub, and individual lab web pages, and many reported models are never published.
1.7.2.5. Incompletely annotated models¶
Many reported models are also not sufficiently well-annotated to combine them into WC models. For example, the biological semantic meaning of a model is often not annotated. This makes it difficult for other researchers to understand the meaning of each variable and equation which, in turn, makes it difficult for other researchers to merge models. The provenance of a model is also rarely annotated. This makes it difficult for other researchers to understand how a model was calibrated, recalibrate the model to represent a different organism and/or condition, and merge a model with models of other organisms and/or conditions. In addition, the assumptions of a model are also rarely annotated. Similarly, this makes it difficult for other researchers to understand how a model was developed, revise a model to represent other organisms and conditions, and merge models from different organisms and conditions.
1.7.3. Inadequate software tools for WC modeling¶
As described in Section 1.4, a wide range of tools have been developed for modeling individual pathways. However, few of these tools support all of the features needed for WC modeling. In particular, few of these tools support the scale required for WC modeling, few of these tools support composite, multi-algorithmic modeling, few of these tools support collaboration, and these tools do not support all of the metadata needed to understand models and their provenance.
1.7.4. Inadequate model formats¶
As described in Section 1.4.2.5, several formats have been developed to describe cell models. However, the lack of a format that supports all of the features needed for WC modeling is a major bottleneck. In particular, no existing format can represent (a) the combinatorial complexity of pathways such as transcription elongation which involve billions of sequence-based reactions; (b) the multiple scales that must be represented by WC models such as the sequence of each protein, the subunit composition of each complex, and the DNA binding of each complex; and (c) multi-algorithmic models that are composed of multiple mathematically-distinct submodels [106].
1.7.5. Lack of coordination among the cell modeling community¶
Another major bottleneck to WC modeling is the lack of coordination among the cell modeling community. Currently, the lack of coordination leads modelers to build competing models of the same pathways and describe models with inconsistent identifiers and formats.
1.8. Technologies needed to advance WC modeling¶
In the previous section, we outlined the major remaining bottlenecks to WC modeling. To overcome these bottlenecks, we must develop a wide range of computational and experimental technologies. Here, we describe the most critically needed technologies to advance WC modeling. In the following sections, we highlight our and others’ ongoing efforts to develop these technologies.
1.8.1. Experimental methods for characterizing cells¶
While substantial data about cellular populations already exists, additional data would enable better WC models. In particular, we should develop new experimental methods for quantitating the dynamics and single-cell variation of each metabolite and protein. Additionally, we should develop methods for measuring kinetic parameters at the interactome scale, as well as methods for measuring cellular phenotypes across multiple genetic and environmental conditions.
1.8.2. Tools for aggregating, standardizing, and integrating heterogeneous data¶
As described in Section 1.4.1.1-1.4.1.2, extensive data is now available for WC modeling. However, this data spans a wide range of data types, organisms, and environments; the data is often not annotated and normalized; it is scattered across many repositories and publications and it is described using inconsistent identifiers and units. To make this data more usable for modeling, we must develop tools for aggregating data from multiple sources; merging data from multiple specimens, environmental conditions, and experimental procedures; standardizing data to common identifiers and units; identifying the most relevant data for a model; and averaging across multiple imprecise and noisy observations.
1.8.3. Tools for scalably designing models from large datasets¶
To scalably build WC models, we must develop tools for defining the interfaces among pathway submodels, collaboratively designing composite, multi-algorithmic models directly from large datasets, automatically identifying inconsistencies and gaps in dynamical models, recording how data and assumptions are used to build models, and encoding models in a rule-based format. As described in Section 1.4.2.2-1.4.2.4, several tools support each of these features. To accelerate WC modeling, we should develop a single tool that supports all of these functions at the scale required for WC modeling.
1.8.4. Rule-based format for representing models¶
Several formats can represent individual biological processes. However, no existing format is well-suited to representing the scale or mathematical diversity required for WC modeling [106][189]. To succinctly represent WC models, we should develop a rule-based format that can (a) represent models in terms of high-level biological constructs such as DNA, RNA, and proteins; (b) represent each molecular species at multiple levels of granularity (for example, as a single species, as a set of sites, and as a sequence); (c) represent all of the combinatorial complexity of molecular biology including the complexity of interactions among protein sites, as well as the complexity of protein-metabolite, protein-DNA, and protein-RNA interactions and the complexity of template-based polymerization reactions such as the combinatorial number of RNA than arise from the interaction of RNA splicing, editing, and mutations; (d) represent composite, multi-algorithmic models; (e) represent the biological semantic meaning of each species and interaction using database-independent formats such as InChI [178] and DNA, RNA, and protein sequences; and (f) represent model provenance including the data and assumptions used to build models.
1.8.5. Scalable network-free, multi-algorithmic simulator¶
To simultaneously represent well-characterized pathways with fine detail and coarsely represent poorly-characterized pathways, WC modeling requires a multi-algorithmic simulator that can scalably co-simulate mathematically-dissimilar submodels that are described using rule patterns. However, no existing simulator supports network-free, multi-algorithmic, and parallel simulation. To scalably simulate WC models, we should develop a parallel, network-free, multi-algorithmic simulator [190]. At a minimum, the simulator should support FBA, ODE integration, and stochastic simulation.
1.8.6. Scalable tools for calibrating models¶
As discussed in Section 1.4.2.9, several tools are available for calibrating small single-algorithm models. However, these tools are not well-suited to calibrating large multi-algorithmic models. To calibrate WC models, we must develop new methods and software tools for scalably calibrating rule-based multi-algorithmic models. We and others have begun to explore using reduced models to efficiently calibrate WC models [179]. However, further work is needed to formalize these methods, including developing automated methods for reducing WC models.
1.8.7. Scalable tools for verifying models¶
To fulfill our vision of using WC models to drive medicine and bioengineering, it will be critical for modelers to rigorously verify that WC models function as intended. As discussed in Section 1.4.2.10, researchers are beginning to adapt tools from computer science and software engineering to verify cell models. However, none of the existing or planned tools support rule-based, multi-algorithmic models. To help modelers verify WC models, we must adapt formal verification and/or unit testing for WC modeling. Furthermore, to help researchers quickly verify models, these tools should help researchers verify entire WC models, as well as help researchers verify reduced models and individual submodels.
1.8.8. Additional tools that would help accelerate WC modeling¶
In addition to these essential tools, we believe that WC modeling would also be accelerated by additional tools for annotating and imputing data, additional tools for sharing WC models and simulation results, additional tools for visualizing simulation results, and community standards for designing, annotating, and verifying WC models.
Tools and standards for annotating data. To make our experimental more useful for modeling, we should develop software tools that help researchers annotate their data and encourage experimentalists to use these tools to annotate their data.
Bioinformatics prediction tools. While existing bioinformatics tools can predict many properties of metabolites, DNA, RNA, and proteins, additional tools are needed to accurately predict the molecular effects of insertions, deletions, and structural variants. Such tools would help WC models design microbial genomes and predict the phenotypes of individual patients.
Repositories for WC models. To help researchers share whole-cell models, BioModels and other model repositories should be extended to support WC models. In addition, these repositories should be extended to support provenance metadata, validation metadata, simulation experiments, and simulation results.
Version control system for WC models. To help researchers collaboratively develop WC models, we should develop a version control system for tracking the changes to WC models contributed by individual collaborators and merging WC model components developed by collaborators. This system could be developed by combining Git [149] with a custom program for differencing WC models.
Simulation format. SED-ML and SESSL can represent simulations of models that are encoded in XML-based formats such as SBML and Java-based formats such as ML-Rules. However, neither is well-suited to representing simulations of models that are encoded in other formats such as BioNetGen. To accelerate WC modeling, we should extend SED-ML to support non-XML-based models or extend SESSL to support other programming languages such as Python and C++.
Database for organizing simulation results. We and others have begun to develop tools for organizing simulation results. However, these tools have limited functionality. To help researchers analyze WC simulation results, we must develop an improved database for simulation results that helps researchers quickly search simulation results for specific features and quickly retrieve specific slices of large simulation results datasets. This database should be implemented using a distributed database and/or data processing technologies such as Apache Spark.
Tools for visualizing simulation results. We and others have also begun to develop tools for visualizing high-dimensional simulation results. However, these tools have limited functionality, they are not easily extensible, and they struggle to handle large datasets. To help researchers analyze WC models to gain new biological insights, we must develop a new tool for visually exploring and analyzing WC simulation results. To enable researchers to incorporate new visual layouts, this tool should support a standard visualization grammar such as Vega [180]. Furthermore, to handle terabyte-scale simulation result datasets, this tools should be implemented using a high-performance visualization toolkit such as VTK [191].
Community standards. To facilitate collaboration, we should develop guidelines for designing WC models, standards for annotating and verifying WC models, and a protocol for merging WC model components. The model design guidelines should describe the preferred granularity of WC model components and the preferred interfaces among WC model components. The standards for annotating and verifying WC models should describe the minimum acceptable semantic and provenance metadata for WC models. The protocol for merging WC model components should describe how to incorporate a new component into a WC model, how to test the new component and the merged model, and how to either accept the new component or reject the candidate component if it cannot be verified or is not properly annotated.
1.9. A plan for achieving comprehensive WC models as a community¶
In the previous sections, we described the potential of WC models to advance medicine and bioengineering, summarized the major bottlenecks to WC modeling, and outlined several technological solutions to these bottlenecks. To maximize our efforts to achieve WC models, we believe that we should begin to develop a plan for achieving WC models. Here, we propose a three-phase plan to achieve the first comprehensive WC model (Figure 1.9). The plan focuses on developing a WC model of H1-hESCs because we believe that the community should initially focus on a single cell line and because H1-hESCs are relatively easy to culture, well-characterized, karyotypically and phenotypically “normal”, genomically stable and relevant to a wide range of basic science, medicine, and bioengineering. Although the plan focuses on a single cell line, the methods and tools developed under the plan would be applicable to any organism, and the H1-hESC model could be contextualized to represent other cell lines, cell types, and individuals.
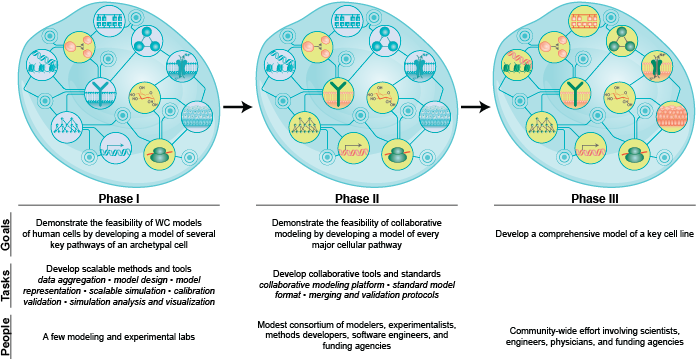
Figure 1.9 The first WC models can be achieved in three phases: (1) demonstrating the feasibility of WC models by developing scalable modeling tools and using them to model several core processes, (2) demonstrating the feasibility of collaborative modeling by developing a collaborative modeling platform and using it to model additional processes, and (3) developing a comprehensive model as a community.¶
1.9.1. Phase I: Piloting the core technologies and concepts of WC modeling¶
Phase I should demonstrate the feasibility of WC models by developing the core technologies needed for WC modeling, and using these tools to build a model of a few critical pathways of H1-hEScs. First, we should develop tools for aggregating the data needed for WC modeling, tools for designing models directly from data, a rule-based format for describing models, tools for quickly simulating multi-algorithmic models, tools for efficiently calibrating and validating high-dimensional models, and tools for visualizing and analyzing high-dimensional simulation results. Second, a small group of researchers should use these tools and public data to build a model of the core pathways of H1-hEScs including several key signal transduction pathways, metabolism, DNA replication, transcription, translation, and RNA and protein degradation. Phase I should also begin to form a WC modeling community by organizing meetings and courses, developing WC modeling training materials, and discussing potential WC modeling standards.
1.9.2. Phase II: Piloting collaborative WC modeling¶
Phase II should focus on demonstrating the feasibility of collaborative WC modeling by developing collaborative modeling tools, and using them to expand the H1-hESc model begun in Phase I. First, we should combine the technologies developed in Phase I into a collaborative web-based WC modeling platform to enable multiple experts to build models together. Second, the community should develop standards for describing, validating, and merging submodels. Third, a modest consortium of modelers and experimentalists should expand the H1-hESc model developed in Phase I by partitioning H1-hESCs into distinct pathways, outlining the interfaces among these pathways, and tasking individual researchers with modeling additional pathways such as cell cycle regulation, DNA repair, and cell division. Fourth, we should extensively validate the combined model. Phase II should also continue to develop the fundamental technologies needed for WC modeling and continue to build a WC community by organizing meetings, courses, and other community events.
1.9.3. Phase III: Community modeling and model validation¶
Phase III should produce the first comprehensive WC model. First, we should assemble a large community of modelers and experimentalists and train them to use the platform developed in Phases I and II. Second, individual researchers should volunteer to model individual pathways and merge them into the global H1-hESc model. Third, we should continue to validate the combined model. Fourth, researchers should use the model to generate testable hypotheses to discover new biology, new disease mechanisms, and new drug targets. Fifth, we should also begin to develop methods for contextualizing the H1-hESC model to represent other cell lines, cell types, and individuals. In addition, the community should continue to develop the core technologies and standards needed for WC modeling, continue to refine the partitioning of cells into pathways, continue to refine the interfaces among the pathways, continue to organize meetings and course, and continue to develop WC modeling tutorials.
1.10. Ongoing efforts to advance WC modeling¶
In the previous section, we proposed a plan for achieving the first comprehensive WC model as a community. Although we do not yet have an organized WC modeling community, we and others are beginning to pilot WC models and the technology needed to achieve them. Here, we summarize the ongoing efforts to pioneer WC modeling.
1.10.1. Genomically-centric models¶
Currently, there are three genomically-centric WC models in development of Mycoplasma pneumoniae, E. coli, and H1-hESCs.
1.10.1.1. Mycoplasma pneumoniae¶
To explore how to build more comprehensive and more accurate models, we are working with Drs. Maria Lluch-Senar and Luis Serrano to develop a comprehensive model that represents all of the characterized genes of the bacterium M. pneumoniae.
M. pneumoniae is a small gram-positive bacterium that has one of the smallest genomes among all known freely-living organisms and that is one of the most common causes of walking pneumonia. M. pneumoniae is tractable to WC modeling because it has a small genome and a small mass; because Dr. Lluch-Senar, Dr. Serrano, and others have extensively characterized M. pneumoniae; and because most of its genome is functionally annotated. However, M. pneumoniae can be difficult to characterize because it grows slowly and because there are few experimental methods for manipulating M. pneumoniae, some aspects of M. pneumoniae are challenging to model because there is no known defined growth media for M. pneumoniae, and the M. pneumoniae research community is small. Because M. pneumoniae has such a small genome, M. pneumoniae is frequently used to study the minimal requirements of cellular life, explore the origins of cellular life, and pilot genome-scale synthetic biology methods such as whole-genome synthesis and genome transplantation. M. pneumoniae is also frequently studied to gain insights into the pathophysiology of walking pneumonia.
The model will be based both on genomic, transcriptomic, and proteomic data about M. pneumoniae collected by Drs. Lluch-Senar and Serrano, as well as a broad range of biochemical and single-cell data about related species aggregated from public databases and publications. In addition to using the model to demonstrate the feasibility of more comprehensive models and drive the development of WC modeling methods, we hope to use this model to engineer a fast-growing, efficient chassis for future bioengineering projects.
1.10.1.2. Escherichia coli¶
To explore how to model more complex bacteria, Prof. Markus Covert and his group at Stanford University are modeling the model gram-negative bacterium E. coli. The project focuses on E. coli because E. coli is the best-characterized bacterium and because there are a wide variety of experimental methods for manipulating and characterizing E. coli. Because E. coli is substantially more complex than reduced bacteria such as M. genitalium and M. pneumoniae, initially, this project will focus on modeling core pathways such as metabolism, RNA and protein synthesis and degradation, DNA replication, and cell division. The model will be based primarily on data observed for E. coli aggregated from a wide range of sources. Prof. Covert and his group are using this model to demonstrate the feasibility of more comprehensive WC models, as well as gain novel insights into the pathogenesis of E. coli.
1.10.1.3. H1 human embryonic stem cells (hESCs)¶
To explore how to model eukaryotic cells, we are also beginning to model H1-hESCs. ESCs are pluripotent cells derived from the inner cell mass of a blastocyst at 4-5 days post-fertilization that can generate all three primary germ layers. We have chosen to pilot human WC models with hESCs because they are karyotypically and phenotypically “normal”; they are genomically stable; they can self-renew; and they are relevant to a wide range of basic science, medicine, and tissue engineering.
Furthermore, we have chosen to focus on H1-hESCs because they can be cultured with feeder-free media and because they have been extensively characterized. For example, H1 was one of the three cell lines most deeply characterized by the ENCODE project [192]. In addition, H1 was one of the first five hESC lines [193], H1 was the first cell line to approved under NIH’s Guidelines for Stem Cell Research, and, as of 2010, H1 was studied in 30% of all hESC studies [194].
Because human cells are vastly more complex than bacteria, we are beginning by modeling the core pathways responsible for stem cell growth, maintenance, and self-renewal, including metabolism, transcription, translation, RNA and protein degradation, signal transduction, and cell cycle regulation. This model will also be based both on genomic, transcriptomic, and proteomic data about H1-hESCs aggregated from publications, as well as biochemical and single-cell data about related cell lines aggregated from several databases. In addition to using the model to demonstrate the feasibility of human WC models and driving the development of WC modeling methods, we hope to use the model to gain new insights into the biochemical mechanisms responsible for regulating the rate of stem cell growth.
1.10.2. Physiologically-centric, spatially-centric, and hybrid models¶
As described in Section 1.6.3-1.6.4, Klipp, Roberts, and others are also developing physiogically-centric models of S. cerevisiae, spatially-centric models of E. coli, and hybrid spatially-centric/FBA models of E. coli.
1.10.3. Technology development¶
Currently, we are developing three technologies for aggregating the data needed for WC modeling; concisely representing multi-algorithmic WC models using rules; and simulating rule-based, multi-algorithmic models.
1.10.3.1. Data aggregation¶
WC modeling requires a wide range of data. Unfortunately, as described in Section 1.7.1, aggregating this data is a major bottleneck to WC modeling because this data is scattered across a wide range of databases and publications. To help modelers obtain the data needed for WC modeling, we are developing a methodology for systematically and scalably identifying, aggregating, standardizing, and integrating the data needed for WC modeling, and we are developing a software program called Datanator which implements this methodology. The methodology consists of eight steps:
Aggregation. Modelers should retrieve a wide range of data from a wide range of sources such as metabolite concentrations from ECMDB, RNA concentrations from ArrayExpress, protein concentrations from PaxDb, reaction stoichiometries from KEGG, and kinetic parameters from SABIO-RK. Where possible, this should be implemented using downloads and web services. Where this is not possible, this should be implemented by scraping web pages and manually curating individual publications. Importantly, modelers should also record the provenance of each downloaded dataset.
Parsing. Modelers should parse each data source into an easily manipulatable data structure.
Standardization. Modelers should standardize the identifiers, metadata, and units of their data. The metadata should include the species and environmental conditions that were observed, the method used to measure the data, the investigators who collected the data, and the citation of the original data. We recommend using absolute identifiers such as InChI to describe all possible measurements, using ontologies such as the Measurement Method Ontology (MMO) to describe metadata consistently, and using SI units.
Integration. Modelers should merge the aggregated data into a single dataset. We recommend that modelers use relational databases such as SQLite to organize their data and make their data searchable.
Filtering. For each model parameter that modelers would like to constrain with experimental data, modelers should identify the most relevant observations within their dataset by scoring the similarity between the physical properties of the parameter and each observation, the species that they want to model and the observed species, and the environmental condition that they want to model and the observed conditions.
Reduction. For each model parameter, modelers should reduce the relevant data to constraints on the value of the parameter by calculating the mean and standard deviation of the relevant data, weighted by its similarity to the physical property, species, and environmental condition that the modeler wants to model.
Review. Because it is difficult to fully describe the context of experimental measurements and, therefore, difficult to automatically identify relevant data for a model, modelers should manually review the least relevant data to potentially select alternative observations or integrate more relevant data from other sources.
Storage. Lastly, modelers should store the reduced data and its provenance in a data structure that is conducive to building models. We recommend organizing this data using a specialized PGDB such as
WholeCellKB.
We have already developed a common platform which implements this methodology, and data aggregation modules for the most critical data types for WC modeling. Going forward, we plan to develop additional modules for aggregating data from a wider range of sources and we plan to develop a user-friendly web-based interface for using Datanator. In addition, we hope to explore additional data aggregation methods such as natural language processing and crowdsourcing.
1.10.3.2. Model representation¶
As described in Section 1.7.4, no existing format is well-suited to representing composite, multi-algorithmic WC models. In particular, there is no format which is well-suited to describing all of the combinatorial complexity of cellular biochemistry, representing composite, multi-algorithmic models, and representing the semantic biological meaning and provenance of models.
To accelerate WC modeling, we are developing, wc_rules, a more abstract rule-based format for describing WC models. The format will be able to represent each molecular species at multiple levels of granularity (for example, as a single species, as a set of sites, and as a sequence); represent all of the combinatorial complexity of each molecular species and interaction; represent composite, multi-algorithmic models; represent the data, assumptions, and design decisions used to build models; and represent the semantic biological meaning of models. We are developing tools to export models described with wc_rules to BioNetGen and SBML, as well as a simulator for simulating models described with wc_rules.
1.10.3.3. Simulation of genomically-centric models¶
As described in Section 1.7.3, no existing simulator is well-suited to simulating computationally-expensive, high-dimensional, rule-based, multi-algorithmic WC models. In particular, there are only a few parallel simulators, only a few rule-based simulators, only a couple of multi-algorithmic simulators, and no simulator which supports all of these technologies.
To accelerate WC modeling, we are beginning to use the Viatra [195] graph transformation engine and the ROSS [117] PDES engine to develop wc_sim, a parallel, network-free, multi-algorithmic simulator that can simulate models described in wc_rules [190]. Simulations will consist of six steps:
Compile models to a low-level format. We will compile models described with
wc_rulesto a low-level format which can be interpreted by the simulation engine.Merge mathematically compatible submodels. We will analytically merge all mathematically-compatible submodels, producing a model which is composed of at most one FBA, one ODE, and one SSA submodel.
Partition submodels into cliques. To use multiple machines to simulate models, we will partition models into cliques that can be simulated on separate machines with minimal communication to synchronize the cliques.
Assign cliques to core. We will use ROSS to assign each clique to a separate machine and use event messages and rollback to synchronize their states.
Co-simulate mathematically-distinct submodels. We will co-simulate the FBA, ODE, and SSA submodels by periodically calculating the fluxes predicted by FBA and ODE models and interpolating them with each SSA event.
Rule-based simulation of SSA cliques. We will use Viatra to represent each species and reaction pattern as a graph and iteratively select reactions, fire reactions, and update the species graphs. To efficiently simulate both sparsely and densely concentrated species, we will use a hybrid population/particle representation in which each species graph will represent a species and its copy number, and we will periodically merge identical graphs that represent the same species.
1.11. Resources for learning about WC modeling¶
To learn more about WC modeling, we recommend attending a WC modeling summer school or participating in the WC modeling forum. Below are brief descriptions of these resources.
1.11.1. Summer schools¶
We and others organize annual WC modeling summer schools [106][196][197] for graduate students and postdoctoral scholars. The schools teach the fundamental principles of WC modeling through brief lectures and hands-on exercises. The schools also provide opportunities to network with other WC researchers. Please see http://wholecell.org for information about upcoming schools.
1.11.2. Online forum¶
The WC modeling forum is an online platform which enables researchers to initiate and participate in discussions about WC modeling.
1.12. Outlook¶
Despite several challenges, we believe that WC models are rapidly becoming feasible thanks to ongoing advances in experimental and computational technology. In particular, in Section 1.9, we have proposed a three-stage plan to achieve comprehensive WC models as a community. The cornerstones of this plan include developing practical solutions to the key bottlenecks; forming a collaborative interdisciplinary community; and adhering to common interfaces, formats, identifiers, and protocols. We have already developed tools for organizing the data needed for WC modeling, organizing WC simulation results, and visualizing WC simulation results, and we have begun to organize a WC modeling community. Currently, we are developing tools for aggregating the data needed for WC modeling, concisely describing WC models, and scalably simulating WC models, and we are continuing to organize WC modeling meetings. We are eager to advance WC modeling, and hope you will join us!